
...making Linux just a little more fun!
Anderson Silva [afsilva at gmail.com]
I took the liberty of creating a Linux Gazette group, if you are a member, show your support by joining:
https://www.facebook.com/group.php?gid=110960368283
Ben, if you are on FB, let me know and I will make your a moderator (and add anyone else as such, as you request).
AS
-- https://www.the-silvas.com
Jimmy O'Regan [joregan at gmail.com]
One of our users is complaining that our transliterator doesn't work; the few of us who have tested it all find that it works for us. Now, he says it only works because our locales are wrong(?). I'm just wondering if anyone other than him can get the incorrect result: i.e., that 'ा' fails to transliterate to 'ા' -- I reproduced the same test using standard tools belo, because they do the same thing as our transliterator.
---------- Forwarded message ----------
From: Jimmy O'Regan <joregan@gmail.com> Date: 2009/8/6 Subject: Re: [Apertium-stuff] Source of trouble: "lt-proc -t" Hindi toGujarati conversion
To: vc9999999@gmail.com, apertium-stuff@lists.sourceforge.net
2009/8/6 Jimmy O'Regan <joregan@gmail.com>:
> 2009/8/6 Vineet Chaitanya <vc@iiit.ac.in>: >> Source of trouble: "lt-proc -t" Hindi to Gujarati conversion: >> >> The "i18n" file which is used for generating locales in the SuSE 11.0 and >> Ubuntu 8.04 version puts Devanagari "maatra" characters under "punct" >> category for LC_CTYPE!!! >> >> >> So Jimmy, Gabriel and Jacob must be using some "non-standard" version of >> "i18n" files for compiling their locales!> > Seriously, so what? Why should that make the slightest bit of difference?
Right...
$ echo $LANG
en_IE.UTF-8
$ echo राम|tr 'राम' 'રામ'
રામ
$ echo राम|sed -e 's/र/ર/g'|sed -e 's/ा/ા/g' |sed -e 's/म/મ/g'
રામ
$ cat s-op.pl
#!/usr/bin/perl
use warnings;
use strict;
while (<>)
{
s/र/ર/g;
s/ा/ા/g;
s/म/મ/g;
print;
}
$ echo राम|perl s-op.pl
રામ
Please try them all.
Rick Moen [rick at linuxmafia.com]
----- Forwarded message from Rick Moen <rick@linuxmafia.com> -----
Date: Fri, 14 Aug 2009 10:48:10 -0700 From: Rick Moen <rick@linuxmafia.com> To: conspire@linuxmafia.comOrganization: Dis-
Subject: [conspire] (forw) [Evals] Joey Hess In The News...Joey Hess, to explain, is a Debian developer who worked with me at VA Linux Systems.
The bit about Palm, Inc. explaining that they're doing nothing that they didn't disclose intention to do in their Privacy Policy (https://www.palm.com/us/company/privacy.html) is worth noting, as this keeps coming up whenever someone discovers user-tracking measures in Google Android phones, Apple iPhones, etc.: Inevitably, there turns out to have been somewhat vague contractual language by which the company made sure it was covered. One of several possible morals: Read contract clauses carefully, and assume the other guy will abuse any right he/she claims to get you to agree to.
Example: Terms of use on Google Docs (https://www.google.com/google-d-s/intl/en/terms.html): Clause 11.1 says:
11.1 You retain copyright and any other rights you already hold in Content which you submit, post or display on or through, the Services. By submitting, posting or displaying the content you give Google a perpetual, irrevocable, worldwide, royalty-free, and non-exclusive licence to reproduce, adapt, modify, translate, publish, publicly perform, publicly display and distribute any Content which you submit, post or display on or through, the Services. This licence is for the sole purpose of enabling Google to display, distribute and promote the Services and may be revoked for certain Services as defined in the Additional Terms of those Services.
"Services" is defined elsewhere as "Google's products, software, services and web [sic] sites". So, in putting your own private data on Google Docs, you are granting Google, Inc. a licence to "reproduce, adapt, modify, translate, publish, publicly perform, publicly display and distribute" your files anywhere on any of its sites provided Google, Inc. can reasonably claim it did so to "display, distribute and promote the Services". Forever: Its right to do so doesn't cease when/if you stop using the service, or even if you cancel your Google login.
Now, for context, I'm not trying to pick on Google, Inc.: Its Terms of Service are, in general, not only quite benign and enlightened but also written in a manner easy for non-lawyers to understand, which is commendable. My point is that, as eyebrow-raising as that particular grant of rights is when you find and comprehend it, the licence agreement as a while is a breath of fresh air compared to most such things.
[ ... ]
[ Thread continues here (1 message/6.87kB) ]
Sandra Davis [sandart3 at msn.com]
[[[ Sent, of course, as html mail. Sigh. -- Kat ]]]
Is Linux a web server such as Firefox? I have never used Linux, but I = have heard of it. Can you tell me why I would use Linux? I read some = about it on the site, but I would like to know why a personal computer = user would want to use this program.
Sandra Davis
[ Thread continues here (20 messages/28.18kB) ]
Nikola Tanev [nikola.tanev at ein-sof.com]
Hello Amit.
Your tutorial for coding a simple packet sniffer has been removed from https://www.ncsu.edu/it/mirror/ldp/LDP/LGNET//128/saha.html
Is it maybe possible that you send it to me via this e-mail
Thank you in advance
Nikola Tanev,
Macedonia
[ Thread continues here (7 messages/9.24kB) ]
Carey Riley [crileyjm at gmail.com]
Greetings:
Do any of you use wicd? I wish to know how to automatically share the wireless on boot. At the moment, the connection to the wired setup is automatically done (by dhcpcd/wicd combination). But the wireless internet sharing has to be set manually.
Thanks in advance.
[ Thread continues here (12 messages/12.87kB) ]
Todd Blake [tbblake at gmail.com]
I've been working on some scripts recently that spawn extra windows, and kill them off for the purposes of displaying images. What I can't figure out is how to programatically lower a window after I've opened it, without delving deeply into some C programming against X that would necessitate a major learning curve.
[ Thread continues here (3 messages/2.63kB) ]
Ben Okopnik [ben at linuxgazette.net]
[cc'd to The Answer Gang]
On Wed, Aug 19, 2009 at 07:42:42AM -0400, Chris Boucek wrote:
> Hello! > > I just wanted to pass a quick thanks to Ben Okopnik. His article on > gnuplot excited me more than discovering the ac command.
Thanks, Chris - always nice to get some feedback! As I recall, we've had a few articles on Gnuplot, R, and similar things since then - even a review of 'Gnuplot in Action' that I did a while back. Hope you have lots of fun exploring it.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * https://LinuxGazette.NET *
Jimmy O'Regan [joregan at gmail.com]
English:
We've just released a new language pair: Norwegian Nynorsk–Norwegian Bokmål, apertium-nn-nb. It's the first released automatic translator for Norwegian developed with the free and open-source Apertium machine translator engine. The pair will be available for testing at at https://www.apertium.org/index.php?id=translatetext .
In developing this system, we used the Free language resources Norsk Ordbank (a full form dictionary with morphological annotations, https://www.edd.uio.no/prosjekt/ordbanken/) and the Oslo-Bergen tagger (a Constraint Grammar disambiguator, https://omilia.uio.no/obt/). Both of these resources are released under the GPL as Free software. Although a lot of conversion work was involved, the availability of high quality Free data led to a much higher coverage (~88%) and accuracy than would have been possible otherwise.
In addition to the reuse and conversion of these existing monolingual resources, a lot of work was done on the translational dictionary (partly assisted by the tool ReTraTos which turns Giza++ corpus alignments into bi-dictionary entries), and we have added transfer rules to handle eg. the differences in passive verbs phrases, gender system and possessive noun phrases.
Future goals include handling simple coordination in possessives, improving the rule-based disambiguator along with retraining the statistical tagger, and of course expanding and improving the translational dictionary.
This language pair was developed as part of a Google Summer of Code (GsoC) project. For more information on Apertium and GsoC, see https://socghop.appspot.com/org/home/google/gsoc2009/apertium . Many thanks to mentors Trond Trosterud (University of Tromsø) and Francis Tyers (Universitat d'Alacant and Prompsit Language Engineering) for advice and help on development, and to the other members of the Apertium project; also to Paul Meurer (Unifob AKSIS) and Kristin Hagen (University of Oslo) for help on the GPL Oslo-Bergen tagger, and to various Wikipedia contributors for help on the translation dictionary. Many thanks to all those who developed the open-source tools and free language resources which contributed in developing this new translator.
For more details on development and the language pair, see https://wiki.apertium.org/wiki/Norsk
Norsk:
Vi har nettopp gjeve ut eit nytt språkpar: nynorsk–bokmål, apertium-nn-nb. Dette er den første automatiske omsetjaren for norsk som er utvikla i med Apertium – ein maskinomsetjingsmotor med fri og open kjeldekode. Språkparet vil vere mogleg å teste på https://www.apertium.org/index.php?id=translatetext?=nn .
[ ... ]
[ Thread continues here (1 message/5.45kB) ]
fairfieldschools@gmail.com [fairfieldschools at gmail.com]
How much does it cost to go into hollywood studios? Your insight into what would be the best way to proceed would be much appreciated. Any info much appreciated. Thank you in advance. Regards, Paul
[ Thread continues here (2 messages/1.17kB) ]
[ In reference to "Installing Perl Modules as a Non-Root User" in LG#139 ]
Vipin TS [vipin.ts at gmail.com]
To whom it may concern,
The article seems to be nice. I tried to work out the same. I configures PERL5LIB variable as
PERL5LIB="/home/galaxy/perl5/lib/perl/5.8.8:/home/galaxy/perl5/lib/perl5:/home/galaxy/perl5/lib/perl/5.8:/home/galaxy/perl5/lib/site_perl"and I put MyConfig.pm file in the /home/galaxy/.cpan/CPAN/ directory. I made editing in LIB and associated things in the MyConfig.pm file And I tried to install some modules that time the perl is looking to install in the default system wide directories not to the assigned locations by the user galaxy. I allocated a place in my home directory thats is
/home/galaxy/perl5 The Error message is *Warning: You do not have permissions to install into /usr/local/lib/perl/5.8.8 at /usr/share/perl/5.8/ExtUtils/Install.pm line 114. Cannot forceunlink /usr/local/lib/perl/5.8.8/auto/Bio/Graphics/Browser/CAlign/CAlign.so: Permission denied at /usr/share/perl/5.8/File/Find.pm line 886 make: [pure_site_install] Error 13*It will be great if you can suggest me a way to overcome this.
-- Vipin T S
[ Thread continues here (2 messages/2.81kB) ]
[ In reference to "How to Reset forgotten Root passwords" in LG#107 ]
Ben Okopnik [ben at linuxgazette.net]
----- Forwarded message from Dmitri Radtchenko <dorscher@gmail.com> -----
From: Dmitri Radtchenko <dorscher@gmail.com> Date: Tue, Aug 11, 2009 at 2:37 PM Subject: Question To: tag@linuxgazette.net
Hello The Answer Gang,
I have a question about the following article: https://linuxgazette.net/107/tomar.html
I did the following:
"Delete everything between the first and second colons, so that the line looks like:" root::12581:0:99999:7:::
"Save the file and exit your editor"
"Type 'reboot' to reboot your system"
However I can't complete this step:
"Now you can log into your system as root with no password. Make sure you change the password immediately."
When I try to login through putty, it asks me for login name, I enter root, then it asks me for password, I just hit enter, and it says the password is invalid.
How exactly do I login with no password?
Thanks!
----- End forwarded message -----
[ Thread continues here (4 messages/4.19kB) ]
[ In reference to "Plotting the spirograph equations with 'gnuplot'" in LG#133 ]
Sonja Schmid [schmid.sonja at gmx.ch]
Dear Víctor Luaña,
I just saw how you drew these labels of the angles in Fig. 1 on page https://linuxgazette.net/133/luana.html . Could you tell me what gnuplot code you use to do so??
Thanks very much in advance!
Sonja
[ Thread continues here (2 messages/5.99kB) ]
[ In reference to "Writing Network Device Drivers for Linux" in LG#156 ]
sai kasavar [saikasavar at gmail.com]
[[[ Eugh, MS-Word html. -- Kat ]]]
Hi,
How does a socket(sock.net/sk_buff.net) is configured with underlying ethernet device structure. I mean at what time the net_device structre is exposed to the socket/sk_buff structure.
Regards
Sai Krishna.
[ In reference to "Keymap Blues in Ubuntu's Text Console" in LG#157 ]
eric stockman [stockman.eric at gmail.com]
On my intrepid ibex 8.10 system the keymaps are in /usr/share/rdesktop/keymaps/
Ben Okopnik [ben at linuxgazette.net]
In using Debian/Ubuntu, I often find myself doing an "apt-cache search <foo>" - i.e., searching the package database. Unfortunately, the copious return from the search often overruns my screen, requiring paging up - or, if I do remember to pipe the output to 'less', turns out to be annoyingly short (and now requires quitting out of the pager.) So, a little while ago, I decided to be lazy^Wefficient and write a script... actually, a function - a script wouldn't do, since the variable I'm looking for only exists in the current shell environment.
From my ~/.bashrc:
ac ()
{
out=$(/usr/bin/apt-cache search "$@")
if [ $(($(echo "$out"|/usr/bin/wc -l)+2)) -ge $LINES ]
then
echo "$out" | /usr/bin/less
else
echo "$out"
fi
}
export -f ac
Using the $LINES Bash variable, which tells us how many lines our current terminal is capable of displaying, makes it relatively simple to decide whether to use a pipe or not. I also adjust the comparison a bit to account for the prompt.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * https://LinuxGazette.NET *
[ Thread continues here (10 messages/12.24kB) ]
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than does an entire press release. Submit items to bytes@linuxgazette.net. Deividson can also be reached via twitter.
 Linux Foundation Updates Linux Development Study
Linux Foundation Updates Linux Development StudyThe Linux Foundation is publishing an update to its April 2008 study on Linux kernel development. The new report reveals trends in Linux development, and hints at topics for an upcoming LinuxCon kernel panel in September.
The new report is written by original authors and kernel developers Jonathan Corbet and Greg Kroah-Hartman, and the Linux Foundation's Amanda McPherson. The August 2009 Update reprises the title "Linux Kernel Development: How Fast it is Going, Who is Doing It, What are They Doing, and Who is Sponsoring It" and is available at https://www.linuxfoundation.org/publications/whowriteslinux.pdf.
The updated study shows a ten-percent increase in the number of developers contributing to each kernel release since April 2008, and that a net of 2.7 million lines of code have been added. This also means an average of 5.45 patches being accepted per hour, up over 40 percent since the original study. Some of the accelerated pace is related to new demand for Linux in emerging markets, such as netbooks, auto, and energy, as well as the new linux-next tree for the next kernel cycle that scales up the development process.
Highlights in the report show that every Linux kernel is developed by nearly 1,000 developers working for more than 200 different corporations; Red Hat, Google, Novell, Intel, and IBM top the list of companies employing developers; an average of 10,923 lines of code are added a day, a rate of change larger than that of any other public software project.
Corbet and Kroah-Hartman will participate on a panel at LinuxCon (https://events.linuxfoundation.org/events/linuxcon/) focused on the kernel development process, and explore some of the trends that surfaced in the new study. Linux creator Linus Torvalds and kernel community members James Bottomley, Arjan van de Ven, and Chris Wright will join them on the LinuxCon keynote panel on Monday, September 21.
Corbet and Kroah-Hartman, also members of the Linux Foundation's Technical Advisory Board (TAB), reviewed the last six kernel releases, from 2.6.24 through 2.6.30, representing about 500 days of Linux development. The report goes into detail on how the Linux development process works, including who is contributing, how often, and why.
Jonathan Corbet is also the editor of Linux information source LWN.net (https://www.lwn.net/), and maintains the Linux Foundation's Linux Weather Forecast (https://www.linuxfoundation.org/collaborate/lwf/).
Greg Kroah-Hartman is a Novell Fellow, working for the SUSE Labs division of the company. He is also the Linux kernel maintainer for the USB, driver core, debugfs, kref, kobject, and sysfs kernel subsystems, and leads the Linux Driver Project: https://www.linuxdriverproject.org/.
Amanda McPherson is vice president of marketing and developer programs at the Linux Foundation, and leads its community relations and event activities.
Coalition to Promote
Benefits of Open Source Software in GovernmentDuring July, a broad cross-section of more than 70 companies, academic institutions, community groups, and individuals joined together to announce the formation of Open Source for America, an organization that will be a unified voice for the use of open source software in the U.S. Federal government arena. To learn more about the coalition, visit https://www.opensourceforamerica.org/.
Gartner recently estimated that, by 2011, more than 25 percent of government vertical, domain-specific applications will either be open source, contain open source application components, or be developed as community source.
The mission of Open Source for America is to serve as an advocate and encourage broader U.S. Federal government participation in free and open source software. Specifically, Open Source for America will help effect change in policies and practices to allow the Federal government to better use these technologies, help coordinate these communities to collaborate with the Federal government on technology requirements, and raise awareness and create understanding among Federal government leaders about the values and implications of open source software.
The diverse Board of Advisors of Open Source for America includes respected leaders such as Roger Burkhardt, Rishab Ghosh, Marv Langston, Chris Lundburg, Dawn Meyerriecks, Eben Moglen, Arthur L. Money, Tim O'Reilly, Stormy Peters, Simon Phipps, Mark Shuttleworth, Paul Smith, Dr. Doug Stone, Michael Tiemann, Andy Updegrove, Bill Vass, Tony Wasserman, and Jim Zemlin.
Founding members of Open Source for America include: Acquia, Alfresco Software, Advanced Micro Devices, Inc., Jono Bacon, Black Duck Software, Inc., Josh Berkus, Ean Schuessler, BrainFood, Canonical, CodeWeavers, CollabNet, Colosa, Inc., Continuent, Danese Cooper, Crucial Point LLC, Josh Davis, Debian, Democracy in Action, Electronic Frontier Foundation, EnterpriseDB, Bdale Garbee, GNOME Foundation, Google, JC Herz, ibiblio.org, Ingres Corporation, Jaspersoft, Mitch Kapor, Kapor Capital, KnowledgeTree, Marv Langston, The Linux Foundation, Linux Fund, Inc., Lucid Imagination, Geir Magnusson, Jr., Medsphere, Mehlman Vogel Castagnetti, Mercury Federal Systems, Monty Widenius, Monty Program AB, Mozilla, North Carolina State University Center for Open Software Engineering, Novell, Open Solutions Alliance, Open Source Initiative, Open Source Institute, Oracle, O'Reilly Publishing, Oregon State University Open Source Lab, Open Source Software Institute, Pentaho, RadiantBlue, Red Hat, Relative Computing Environments LLC., REvolution Computing, Walt Scacchi, Institute for Software Research at UC Irvine, Software Freedom Law Center, SpikeSource, SugarCRM, Sunlight Labs, Sun Microsystems, School of Engineering, University of California, Merced, University of Southern Mississippi, Andy Updegrove, Gesmer Updegrove LLP, Tony Wasserman, Center for Open Source Investigation, Carnegie Mellon Silicon Valley, Zenoss, Inc., Zimbra, and Zmanda.
For recent open source developments in government, go here: https://www.opensourceforamerica.org/case-studies/
Google Announces Plan for New Linux-based Chrome OSIn July, Google informed readers of its corporate blog that it was working on a new, light-weight operating system to support a new Web application platform for PCs and mid-range Internet devices. This will be based on the Linux kernel, but will have a new windowing sub-system. Since it was designed to work with the Chrome Web browser, Google referred to its planned OS as the Chrome OS.
"Google Chrome OS is an open source, lightweight operating system that will initially be targeted at netbooks. Later this year, we will open-source its code, and netbooks running Google Chrome OS will be available for consumers in the second half of 2010."
The blog entry goes on to draw some distinctions with its on-going Android OS project for smart phones: "Google Chrome OS is a new project, separate from Android. Android was designed from the beginning to work across a variety of devices from phones to set-top boxes to netbooks. Google Chrome OS is being created for people who spend most of their time on the Web, and is being designed to power computers ranging from small netbooks to full-size desktop systems."
The goals for the new operating systems are speed, simplicity, and security as well as expanding the power of Web applications. A fast boot of only a few seconds is another design goal.
A few weeks earlier at the O'Reilly Velocity Conference, Google VP of Search Product and User Experience Marissa Mayer spoke at a keynote and announced Google initiatives to improve the performance of both Web pages and Web applications. These included the public release of new performance measuring tools such as PageSpeed and the Google "Speed" Web site, which will feature discussions and tech talks on performance issues. See https://code.google.com/speed/.
In her keynote, Mayer said that Google would continue to work on improving performance at the page design level, the browser level, and the server level. Chrome OS is clearly part of that effort as well.
In June, Google created a Web site focused on making Web applications, sites, and browsers faster. The developer site supports Google's decision to share its best practices with tutorials, tips, and performance tools. Google hopes to make the Web faster by aiding developers interested in Web application performance.
Google made the announcement at the June O'Reilly Media's Velocity conference in San Jose, California, an event focused on Web performance. Featured in several Google-sponsored presentations, the Web site offers new performance tools such as Page Speed, an augmented version of YSlow to analyze the interaction between Web browsers and Web servers.
Back in December, Google announced its Native Client Code project, which aims to create a secure framework for running native code over the Web. The goal here is to develop "...a technology that seeks to give Web developers the opportunity to make safer and more dynamic applications that can run on any OS and any browser." One aspect of this is to use reliable disassembly, and a code validator to determine if any executable includes unsafe x86 instructions. See: https://googleonlinesecurity.blogspot.com/2008/12/native-client-technology-for-running.html
According to Amanda McPherson, VP of Marketing and Developer Programs at The Linux Foundation, "...Google's Native Application Project will be a key part of this OS," which will result in making "...more of the computing power of the device than through the normal app/browser paradigms of today." She adds that this approach can minimize the current advantages of (Windows) native applications and "...should grow the stable of applications for Chrome, and every other Web browser who makes use of this technology."
She sees the Google model as providing better performance and boot times on devices that are cheaper to make and don't carry the Microsoft OS tax. Her blog entry is available here: https://www.linux-foundation.org/weblogs/amanda/2009/07/09/what-is-googles-goal-with-its-chrome-os/
In his blog posting on the day of the announcement, Jim Zemlin, executive director of the Linux Foundation, wrote that this is a victory for Linux and its community development model: "We look forward to seeing Google collaborate closely with the Linux community and industry to enhance Linux as the foundation for this new computing model."
See his full posting at: https://www.linuxfoundation.org/news-media/blogs/browse/2009/07/linux-clear-winner-google-os-news/. In its Chrome OS FAQ, Google mentions that it is working with Acer, Adobe, ASUS, Freescale, Hewlett-Packard, Lenovo, Qualcomm, Texas Instruments, and Toshiba, among others.
Gartner, IDC Report PC Market Down Less than 5%The PC market fell less than expected in the last quarter, according to research firms Gartner and IDC. Both firms released numbers in mid-July showing the global PC market fell less than the 6.3-9.8 percent decline expected. Gartner said the market slipped 5 percent, while IDC said the market fell only 3.1 percent.
In terms of market share, Hewlett-Packard grew its lead as the #1 PC vendor with almost 20% of the market, while Dell slipped further to about a 14% share. Acer was #3 with a 12.7% market share.
Sandia Labs boots one million Linux virtual machinesComputer scientists at Sandia National Laboratories in Livermore, California, have successfully run more than a million Linux kernels as virtual machines.
The achievement will allow cyber-security researchers to model behavior found in malicious botnets, or networks of infected machines on the scale of a million nodes.
Sandia scientists used virtual machine (VM) technology and the power of its Thunderbird supercomputing cluster for the demonstration.
Running a high volume of VMs on one supercomputer - at a similar scale as a botnet - allows cyber-researchers to watch how botnets work and explore ways to stop them.
Previously, researchers had only been able to run up to 20,000 kernels concurrently. (A "kernel" is the central component of most computer operating systems.) The more kernels that can be run at once, he said, the more effective cyber-security professionals can be in combating the global botnet problem. "Eventually, we would like to be able to emulate the computer network of a small nation, or even one as large as the United States, in order to 'virtualize' and monitor a cyber-attack," he said.
A related use for tens of millions of operating systems, Sandia's researchers suggest, is to construct high-fidelity models of parts of the Internet.
"The sheer size of the Internet makes it very difficult to understand in even a limited way," said Sandia computer scientist Ron Minnich. "Many phenomena occurring on the Internet are poorly understood, because we lack the ability to model it adequately. By running actual operating system instances to represent nodes on the Internet, we will be able not just to simulate the functioning of the Internet at the network level, but to emulate Internet functionality."
The Sandia research, two years in the making, was funded by the Department of Energy's Office of Science, the National Nuclear Security Administration's (NNSA) Advanced Simulation and Computing (ASC) program and by Sandia itself.
To complete the project, Sandia used its Albuquerque-based 4,480-node Dell high-performance computer cluster, known as Thunderbird. To arrive at the one million Linux kernel figure, Sandia's researchers ran 250 VMs on each of the 4,480 physical machines on Thunderbird. Dell and IBM both made key technical contributions to the experiments, as did a team at Sandia's Albuquerque site that maintains Thunderbird and prepared it for the project.
The capability to run a high number of operating system instances inside of virtual machines on a high performance computing (HPC) cluster can also be used to model even larger HPC machines with millions to tens of millions of nodes that will be developed in the future, said Minnich. The successful Sandia demonstration, he asserts, means that development of operating systems, configuration and management tools, and even software for scientific computation can begin now before the hardware technology to build such machines is mature.
"It has been estimated that we will need 100 million CPUs (central processing units) by 2018 in order to build a computer that will run at the speeds we want," said Minnich. "This approach we've demonstrated is a good way to get us started on finding ways to program a machine with that many CPUs." Continued research, he said, will help computer scientists to come up with ways to manage and control such vast quantities, "so that when we have a computer with 100 million CPUs we can actually use it."
Ultra-large clusters can be used for modeling climate change, developing new medicines, and research into the efficient production of energy. "Development of this software will take years, and the scientific community cannot afford to wait to begin the process until the hardware is ready," said Minnich.
Bing Trims Yahoo's Search Share, not Google'sOn the search front, in spite of its multi-million dollar advertising campaign and positive critical reviews, the new search engine "Bing" hardly moved the dial on search statistics. According to a report from comScore.com, in June Google held steady at 65% of searches. Microsoft sites rose from 8% to 8.4%, while Yahoo sites fell from 20.1% to 19.6%.
In a related conference call, Google told the press that it sees users writing longer and more sophisticated search queries. That may account for Google's stable statistics. Google is trying to respond with new options and more specialized search domains.
Americans conducted 14 billion searches in June, down slightly from May. Google Sites accounted for 9.1 billion searches, followed by Yahoo! Sites (2.8 billion), Microsoft Sites (1.2 billion), Ask Network (552 million) and AOL LLC (439 million). Facebook.com experienced the highest growth of the top ten expanded search properties with a 9% increase.
For more information, visit comScore.com and read the press release at https://comscore.com/index.php//Press_Events/Press_Releases/2009/7/comScore_Releases_June_2009_U.S._Search_Engine_Rankings/.
SimplyMEPIS 8.0.10 ReleasedThe beginner-friendly distro and live CD SimpleMEPIS has just released a new version, based on Debian 5.0 "Lenny", enhanced with a long-term support kernel and with the MEPIS Assistant applications, aiming to create an always updated, easy-to-use system.
The new version includes, along with the updates from "Lenny", updates to the MEPIS installer and MEPIS utilities, plus several package updates, including Firefox 3.5.2, Google Gadgets 0.11.0, and much more.
More information can be found on the release notes (https://www.mepis.org/node/14222/), and the download links can be found here: https://www.mepis.org/mirrors/.
Fedora 12 Alpha GA AnnouncedThe first public development release of Fedora 12 "Constantine" was announced last month, and it includes several new features, including out-of-the-box support for many new webcam models, several updated packages, a better free video codec, PackageKit improvements, better power management, and several other updates.
More information can be found here: https://fedoraproject.org/wiki/Fedora_12_Alpha_Announcement/ and download links can be found here: https://mirrors.fedoraproject.org/publiclist/Fedora/12-Alpha/.
Canonical releases source code for LaunchpadIn July, Canonical, founder of the Ubuntu project, announced it had open-sourced the code that runs Launchpad, the software development and collaboration platform used by tens of thousands of developers. Launchpad is used to build Ubuntu and other FOSS projects.
Launchpad allows developers to host and share code from many different sources using the Bazaar version control system, which is integrated into Launchpad. Translators can collaborate on translations across many different projects. End-users identify bugs affecting one or more projects so that developers can then triage and resolve those bugs. Contributors can write, propose, and manage software specifications. In addition, Launchpad enables people to support each other's efforts across different project hosting services, both through its Web interface and its APIs.
"Launchpad accelerates collaboration between open source projects," said Canonical founder and CEO Mark Shuttleworth. "Collaboration is the engine of innovation in free software development, and Launchpad supports one of the key strengths of free software compared with the traditional proprietary development process. Projects that are hosted on Launchpad are immediately connected to every other project hosted there in a way that makes it easy to collaborate on code, translations, bug fixes, and feature design across project boundaries. Rather than hosting individual projects, we host a massive and connected community that collaborates together across many projects. Making Launchpad itself open source gives users the ability to improve the service they use every day."
"Since the Drizzle project's start in April 2008, its community and contributors have used Launchpad as a platform for managing code and development tasks, and as an efficient method of communication between community members regarding bugs, workflow, code reviews, and more." said Jay Pipes, Core Developer on the Drizzle Project at Sun Microsystems. "Launchpad makes it easy to take all the disparate pieces of software development - bug reporting, source control, task management, and code reviews - and glue them together with an easy-to-use interface that emphasizes public and open community discourse."
Launchpad hosts open source projects for free, but closed source projects use the service for a fee. This means that projects can use the features that Launchpad provides but do not need to share code if that is not desirable. The privacy features are currently in beta, and will be added to the commercial service as they become available.
Technical details about the open-sourcing can be found at https://dev.launchpad.net/.
Penguin Computing Launches HPC in the CloudPenguin Computing announced the availability of "Penguin on Demand" - or POD - a new service that delivers high performance computing (HPC) in the cloud. POD is targeted at researchers, scientists, and engineers who require surge capacity for time-critical analyses.
"The most popular cloud infrastructures today, such as Amazon EC2, are not optimized for the high performance parallel computing often required in the research and simulation sciences," said Charles Wuischpard, CEO at Penguin Computing. "POD delivers immediate access to high-density HPC computing, a resource that is difficult or impossible for many users to utilize in a timely and cost-effective way."
POD provides a computing infrastructure of highly optimized Linux clusters with specialized hardware interconnects. Rather than using machine virtualization, as is typical in traditional cloud computing, POD allows users to access a server's full resources and I/O at one time for maximum performance and massive HPC workloads.
Based on high-density Xeon-based compute nodes coupled with high-speed storage, POD provides a persistent compute environment that runs on a head node and executes directly on compute nodes' physical cores. Both GigE and DDR high-performance Infiniband network fabrics are available. POD customers also get GPU supercomputing with Nvidia Tesla processor technology. Jobs typically run over a localized network topology to maximize inter-process communication, to maximize bandwidth, and to minimize latency.
Penguin Computing offers support and services for POD customers, including application set-up, creation of the HPC computing environment, ongoing maintenance, data exchange services, and application tuning. In addition, POD includes persistent storage for local data and user-defined compute environments.
For more information about Penguin on Demand (POD), please go to https://www.penguincomputing.com/POD/Penguin_On_Demand/.
PlateSpin Migrate Supports P-to-V Migrations for SolarisIn July, Novell announced the addition of physical-to-virtual migration support for Sun's Solaris 10 operating system in the latest version of PlateSpin Migrate, their workload management product to move workloads anywhere to anywhere: between physical, image, virtual, and cloud environments.
PlateSpin Migrate 8.1 offers workload migration product support for Solaris Containers, giving customers the ability to migrate workloads from physical to virtual environments. The latest version of PlateSpin Migrate significantly expands the already broad list of platforms supported for physical to virtual migration, by adding support for the recently released SUSE Linux Enterprise 11 from Novell to the existing support for prior versions of SUSE Linux Enterprise. PlateSpin Migrate 8.1 also adds support for Windows 2008 and Windows Vista.
"We expect PlateSpin Migrate 8.1 to make it even easier for customers to take advantage of the power and versatility of Solaris Containers," said Jim McHugh, vice president of Data Center Software Marketing at Sun. "Using PlateSpin Migrate 8.1 to perform physical-to-virtual migration will also help minimize the risk of introducing errors into new configurations and speed the completion of virtualization projects."
PlateSpin Migrate 8.1 makes it easy to migrate workloads between physical servers, image archives and virtual hosts. PlateSpin Migrate also offers performance improvements for business-critical workload migrations, making increased use of block-based transfer technology that transfers only the portion of the file that has changed. This innovation limits the amount of downtime during the migration process, and improves migration performance, especially over slower and expensive WAN connections.
PlateSpin Migrate 8.1 is available now. The Windows/Linux version is priced at $289 for a workload license. PlateSpin Migrate for UNIX is priced at $1,495 for a one-time license. For more information about this announcement, see https://www.platespin.com/products/migrate/.
Sun Releases NetBeans 6.7 with Project Kenai At the end of June, the NetBeans developer community announced NetBeans Integrated Development Environment (IDE) 6.7. This new version of NetBeans features tight integration with Project Kenai, Sun's collaborative hosting site for free and open source projects. Developers can download the free, full-featured NetBeans IDE 6.7 at https://www.netbeans.org/.
The integration between NetBeans and Kenai allows developers to stay in their IDE and navigate between Kenai.com, local code, bug reports, IM chats, and project wikis. This integration allows developers to discuss, edit, debug and commit code through one easy-to-use interface. Other key features of NetBeans IDE 6.7 include:
Integration with Kenai.com will allow developers to stay in the IDE to create projects in the cloud; get sources from Kenai projects; and query, open and edit issues for them using Bugzilla. NetBeans IDE users can stay connected with other team members with an integrated chat, Kenai's user profiles, wikis, and mailing lists. Learn more about Project Kenai at https://www.kenai.com/.
Other highlights of the NetBeans IDE 6.7 release includes improved PHP and GlassFish software support. The NetBeans IDE provides a rich set of features for Ruby, Groovy, and JavaScript and other technologies. Support for JavaFX 1.2 technology is currently available for NetBeans IDE 6.5.1 and will soon be available for NetBeans IDE 6.7. Learn more at https://www.netbeans.org/features/.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.

VMware World is up first this year, and it actually starts on August 31. The venue is San Francisco again after a brief hiatus to San Diego. Two years back, this was a very solid conference, and I expect more of the same this year. To some extent, they have to do well, considering the increasing competition in virtualization space.
The opening keynote is on September 1, so this is technically a September conference.
The conference "Party!" is on Wednesday evening, September 2, and takes place at both Moscone Center and Yerba Buena Gardens, outside. Options will include riding a mechanical bull, rock climbing, and laser tagging your colleagues. They say there will be a food court, with food from around the world, but I think this will be potstickers and pasta. But there's got to be beer.
The party headline act is Foreigner, performing classic hits like "Cold As Ice", "Feels Like The First Time", and "Double Vision" .
TAM Day is a one-day event on August 31, designed exclusively for VMware Technical Account Manager (TAM) customers, which showcases new VMware virtualization technologies plus road-map sessions. TAM Day also includes a Birds of a Feather luncheon, where you can sit with subject matter experts in small groups. The event is free for any current TAM customer who attends VMworld; if you don't qualify, you can still pay for one of many tutorials.
At VMworld 2007 in SF, the ESX hypervisor was the big news. VMware Infrastructure was also a hot topic, and was covered in several technical sessions. Its next rev - vSphere - should be a hot topic this year.
The 2007 VMware World featured classes, labs, panels, and tutorials, plus interesting keynotes. Inside the conference backpack, which was substantial, was a USB drive loaded with VMware ESX 3, their high-end hypervisor, which was not free at the time. Couple that with great meals and snacks, and you have something to look forward to.
Most of the content from VMworld finds its way to VMworld.com. You have to register there first, but it's free. Here's a link with agenda information from VMworld 2007: https://www.vmworld.com/community/conferences/2007/agenda/. And here's a link to highlights from recent VMworld conferences in the US and in Europe, which includes "Virtualized Oracle Server Performance": https://www.vmworld.com/community/sessions/.
On a counter swing, Digital ID World moves from SF to Las Vegas this year. It will be held at the Rio, September 14-16. The long-running forum on identity in the digital world is sponsored by Digital ID magazine. This is the place to discuss federated identity, OpenID vs CardSpace, identity governance frameworks, WS-Trust, and SAML.
In 2008, speakers included Doc Searls, Senior Editor, Linux Journal; Kim Cameron, Architect of Identity, Microsoft Corporation (who is very friendly to open source); and Jamie Lewis, CEO and Research Chair, Burton Group.
Besides good speakers and great discussions on identity issues, this conference has historically had great desserts!
Here's the link to the conference page for Digital ID World 2008: https://public.cxo.com/conferences/index.html?conferenceID=24
Click the post conference tab to get to PDF files and MP3 audio from some sessions.
And here's the link to Digital ID World 2009: https://public.cxo.com/conferences/index.html?conferenceID=51
All of IDF 08 fit nicely into the new Moscone West building, which is across the street from the main North and South halls. Just go up and down the escalators to get to sessions on the second and third floor. Actually, most sessions were on two long corridors on Moscone Convention Center's second floor.
The tech tracks are well managed and keep closely to the set time. That's important with 50-minute session times. Audience Q/A is also very limited, due to the short session format. Sit near the microphone if you have questions, and be first or second up to the mic.
I think there were fewer concurrent sessions in 2008 than there were in 2007. Several labs were run only once or twice (in a single day), rather than repeatedly over the week as in earlier years. That did lead to a lot of standing-room-only sessions. Anticipating the most popular sessions and arriving early is a helpful art. On the other hand, several of those were supposed to be be posted on-line.
The food is a carnivore's delight and certainly a bit light on plant food. Your veggie friends may go a bit hungry at lunch. However, Intel and other co-sponsors did provide a variety of veggie items at the evening Expo receptions.
Here's where to find a long list of technical tracks for IDF 09: https://www.intel.com/idf/technology-tracks/
These include, among other topics, Mobile Tech, Moblin, Intel Virtualization, Extending Battery Life, Eco-tech, 32 nanometer microarchitecture, Super Speed USB, Public Clouds, Next Gen PCI, etc.
IDF will continue with Intel's focus on mobility in computing. Last year, Intel gave its Moblin project over to the Linux Foundation, but Intel engineers continue to be the bedrock of Moblin.
The 2008 Keynote info is here: https://www.intel.com/idf/us/fall2008/highlights/keynotes.htm?iid=idf+BottomNav+ForumHighlights+Keynotes
I expect live streams and archive info on that link later.
The 2008 session catalog is here: https://intel.wingateweb.com/US08/scheduler/controller/catalog
And here is a list of the 2008 technology tracks: https://www.intel.com/idf/us/fall2008/training/topics.htm?iid=idf+MarqeeNav+Subnav+Training+Topics
Also don't forget the new events hosted by the Linux Foundation: 1st Annual LinuxCon and 2nd Annual Linux Plumbers Conference, both in Portland, OR., September 21-23 and September 23-25. Follow the links for more info: https://events.linuxfoundation.org/events/linux-con/ and https://linuxplumbersconf.org/2009/
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.
By Lisa Kachold

Linux users and system administrators are often unable to sufficiently focus on general system changes, log data, and tracking what they did and when to detect if their systems have been encroached upon.
Not all of us can afford an in-line Layer 7 switch, Cisco ASA, or IDS. During escalated security events, it takes time to set up, e.g., Snort - which does not detect all encroachments. (See Matahari, below.) Additionally, production systems are often under high change control, or utilized so fully that their CPU/memory capacity is unable to field additional daemons.
Snort can be quickly set up via Live CD, Backtrack, DVL, or other security tools. A Snort tcpdump can be taken during off-peak hours for import and full rules-check against a variety of aggressive Layer 4-7 de-network engineering attempts:
https://www.freeos.com/articles/3496/
Snort doesn't always see all possible security exploits, however. While it will evaluate packet traffic in the upper OSI layers, it will miss backdoors, and binary rootkits. It will also miss shell or SSH access from past disgruntled staff, unauthorized employees, and other admins or users.
Keyloggers can be a quick honeypot addition, as you evaluate deeper-level kernel, network, disk, and binary veracity after a suspicious security event.
CERT recommends that any suspect server be rebuilt, but system administrators are often remiss in obtaining proof, right up until "pwnership" creates escalated reactivity where uptime is only a dream. Every one of us knows that ownership is equated to stability in America, right?
https://www.cert.org/tech_tips/win-UNIX-system_compromise.html
Not all that glitters is gold, however: keyloggers can act as a part of a honeypot, be a component of PCI compliance, part of Sarbanes-Oxley (SOX) audit tools, change management or system administration utilities - or be a part of Trojan viruses. Certainly, a great deal of system penetration and changes are done without using a shell (e.g., webmin, sftpd, httpd/DAV writes, and low level binary trojans - see Snort or Autopsy).
It's becoming more and more common to log all root keystrokes in layers of trust and secrecy that users, developers, and even system administrators don't immediately recognize.
The three most often deployed keyloggers in Linux systems include:
While PAM hacking and modifications is a whole subject in and of itself, various keyloggers can be deployed using PAM. The "rootsh" utility - which allows you to enable a systems logger that will show everything logged to the terminal whenever anyone invokes sudo or logs in as a user - is a great immediate solution.
https://freshmeat.net/projects/rootsh/
General implementation recommendations include renaming "rootsh" to another seemingly innocuous sounding word - like "termd".
"rootsh" is immediately useful, especially if you have more than one system administrator or root user (although you should always disable root access completely in favor of logged sudo).
It's often too late when we realize that our sudoers file was not configured to be limited to only a select list of users, or was not logging (e.g., if we have inherited 200 machines installed with stock sudo -- see my August 2009 Linux Gazette "Layer 8 Linux Security" column on maintaining sudo via Puppet). So, perhaps it went unnoticed that a past disgruntled developer was accessing the system from his desktop via RDP to SSH and accessing root regularly via 'sudo su'.
In startup ISPs and Web development shops in the mid-1990s, a "Nazi" Linux security administrator would often tire of being on-call 24x7 in an uncontrollable server farm, and come down with the avant-garde edict of "no shared root access", whereupon all developers just took escalated access via escaping system calls from emacs or vi, or via buffer overflows, and happily changed the access passwords for users: games, haldaemon, adm, lp, or sync. Similar shops and Linux un-professionals still exist, unfortunately.
Since any access to root via sudo can result in changes (and potential errors), a good keylogger makes a lot of sense as an easily setup secondary tracking mechanism.
PCI compliance and SOX both require controls in place for the root or administrative user. However, when mixed with corporate profit, these controls are loosely interpreted to the point of complete insecurity. If we cannot track change, we control nothing. Implementing a keylogger will take no more than fifteen to thirty minutes (and can easily be automated through Puppet), so if you suspect your systems of being accessed and the logs being wiped, or if you don't have the time to fully evaluate all binary checksums for rootkits, keyloggers can be a good immediate additional security tool.
By default, 'rootsh' logs to /var/log/rootsh/ (which can be changed during setup). Of course, 'rootsh' logs can be edited, like any logs, unless you use 'syslog-ng', or stunnel loghost or cron-based e-mail log burst, so hide them well. You will generally find that no one even notices that 'rootsh' is logging, and happily carry on as normal.
You might not have a Honeywall server, but Sebek clients (with Honeywall servers) provide nearly invisible logging capacity for honeypot and system administration monitoring.
"https://www.honeynet.org/tools/sebek/>
Sebek is a kernel module that is also available for Windows machines.
Honeywall and other honeypots can be set up to poll selectively. They can be moved in during the middle of the night, and can be set up with clients to your servers, from a Live CD/DVD, via VM or Xen virtualization. They should definitely be included as an adjunct to your disaster recovery plan/stack.
https://www.honeynet.org.es/papers/vhwall/
https://www.jessland.net/JISK/Honeypots/Tools.php
Too late to plan, can't change extensive system networking or add kernel mods? Configure honeymole:
https://www.honeynet.org.pt/index.php/HoneyMole
These masquerade as USB-to-PCI or other conversion tools, and are most often deployed at NOCs with KVMs.
"https://www.keelog.com/download.html
Hardware-based keyloggers are especially useful in that they work across platforms, provide nearly instant results, and can be reused. However, the most-savvy system administrators usually see the terminal pause and flash that accompany use of a hardware logger on a KVM. But it's possible that someone accessing your NOC via keyboard/console after a quick lock pick (certainly, no one will ever verify the cameras -- those only retain 3 days of footage) or logging into your systems before rifling your cabinets won't notice your keyloggers at all.
Neither "find -mtime", nor careful evaluation of all processes, nor even a stack trace will ever see a hardware key; even really astute hackers with well-honed senses often cannot even determine the source in hardware keyloggers.
The legal ramifications of micro-critiquing a system administrator or engineer for making general typing mistakes are problematic due to the non-exempt Federal statutes for professionals (since the FLSA standards require us to be able to work without micro-direction) - but be advised that all high-level responsible actions are logged post-2001 in America. While setting up your keyloggers, don't be surprised if you discover management or security have deployed one of their own.
Even at the application Web layer, many large online providers deploy Akamai caching. Federal security monitoring includes Akamai integration with various pipe taps, gleaning databases of packet and user access for individuals "of interest" (cross-matching e-mail or other authentication cookie info) across cellphone, cable, and dial-up Internet. Monitoring information equals power in small and large systems across all OSI layers.
Trojan keyloggers are extensive in variety, attack vector, and application, from those used by the FBI to log mob boss encryption PGP passphrases, to browser-based plugins. They include XSS tunnels, LivePerson, etc., and are all trivially deliverable via Sharepoint, GMail, Yahoo, or other Web-based e-mail, in HTML/Javascript or URI/UTF-8, PDF, JPG, Word/OpenOffice, or other executable "attack-ments".
https://www.cert.org/tech_tips/securing_browser/
[ Much of the above is not trivial by any means, or even possible in most situations, especially if you're running Linux; some of the attack types listed here (e.g., keylogger delivery via JPG) exist only as concepts. It is, however, worth noting that new attack methods are discovered constantly, that a lot of money is being pumped into attack development daily, and that any active (i.e., executable) attachment should be regarded with extreme suspicion. -- Ben ]
Matahari is designed to provide a basic non-interactive shell on remote systems behind firewalls. It is intended for use by system administrators who may need some emergency backdoor to access a firewalled machine.
Once you set up the script on the target machine (namely, the client) it begins trying to retrieve commands from the master machine (the server). The time between periodic requests (polls) can be configured to suit different needs, ranging from low latency (frequent polls) to stealthier behaviors.
All traffic between target and master machine is made through HTTP GET/POST requests and their corresponding responses, traversing firewalls as standard outgoing Web traffic. Optional IDS-evasion techniques can be used in special scenarios where a backdoor should remain totally undetected by firewall administrators.
Matahari.py's HTTP port is configurable; Snort and many IDSes do not intercept Matahari packets. The script must be set up on both sides, and is available on Backtrack (KDE --> Maintaining Access --> BackDoors and Rootkits), or from here:
https://sourceforge.net/projects/matahari/files/matahari/0.1.25/
Suspect your server has been compromised? Watch for rogue Python processes (renamed to something that sounds perfectly believable like "updatd") and/or Matahari running from anacron (which is often left enabled yet ignored) that opens scheduled tunnel access.
Turn the tables! Matahari is also exceptional as an administrative security honeypot tool to watch a compromised server for information-gathering purposes without the crackers catching on, should you not want to possibly expose additional systems like a logserver, and have limited setup time.
Matahari usage:
If you have a target machine (target.freemoney.com) behind your firewall, and want to be able to execute commands from a master machine (master.obnosis.com):
# On the target machine: ./matahari.py -c master.obnosis.com -T polite
Use nohup and screen, to be sure process still runs after log off.
# On the master machine: ./matahari.py -s target.freemoney.com
Reference: https://matahari.sourceforge.net/
Always take a 'dd' (a disk image created by the 'dd' program) for analysis in Autopsy, available from the Backtrack Live CD tools. A terabyte USB disk or NAS/SAN makes disk imaging easy.
Depending on the event in question, a complete security evaluation/audit might be required to determine the attack vector and to mitigate the risks. This should take precedence over forensics, once the first sign of proof is found. In an active attack situation, failing to act is an act leading to fail. Any recovery model that mandates simply rebuilding without identification of application-layer issues, physical security issues, or acceptable use/change management policy holes will leave you destined to rebuild regularly and often, or wear the "security issue" blinders and consistently walking away from obvious signs of encroachment.
Most users, developers, and system administrators find it trivial to rebuild and harden a system, then 'dd' its pristine state to a backup archive before ever bringing it up, so they can restore state as necessary - assuming that such an archive exists.
Any system use model that includes an easy rebuild window is a secure model. Backing up important files is required for users, developers, and administrators alike. Puppet or cfengine can reconfigure a system swiftly, while kickstart/jumpstart can provide network-based rebuilds using seed files.
The single greatest security problem today is ignoring danger or failing to look for proof when faced with questionable events or evidence. All users, developers, and administrators hold direct responsibility to identify, report, prove, and resolve all areas where secure processes break down across any of the OSI layers.
References:
Keyloggers: "https://en.wikipedia.org/wiki/Keystroke_logging#Remote_access_software_keyloggers
Matahari: https://thewifihack.com/blog/?p=58
Snort: https://freshmeat.net/projects/snort/
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/kachold.jpg)
Lisa Kachold is a Linux Security/Systems Administrator, Webmistress, inactive CCNA, and Code Monkey with over 20 years Unix/Linux production experience. Lisa is a past teacher from FreeGeek.org, a presenter at DesertCodeCamp, Wikipedia user and avid LinuxChix member. She organized and promotes Linux Security education through the Phoenix Linux Users Group HackFEST Series labs, held second Saturday of every month at The Foundation for Blind Children in Phoenix, Arizona. Obnosis.com, a play on a words coined by LRHubbard, was registered in the 1990's, as a "word hack" from the Church of Scientology, after 6 solid years of UseNet news administration. Her biggest claim to fame is sitting in Linux Torvald's chair during an interview with OSDL.org in Oregon in 2002.
Exactly ten years ago, I was writing my very first article for the Linux Gazette. Back in 1999 I was a college student with some interest in education and a somewhat new Linux user. I wrote a short article about my own experience with the programming language Logo. In that article, I stated:
Today I am 21 years old, and I still like playing around with Logo. And I will use it to teach my son a little bit about programming and discrete math concepts.
Well, it's now 2009, and I am 31 years old. I have three kids, and I am teaching them some basic concepts in programming, geometry, and discrete mathematics with Logo. During the past ten years, much has changed. Linux has matured to levels where even Microsoft is contributing code to the kernel, and yet, Logo still remains mostly the same. In the original article I had to compile the interpreter from source, and I couldn't even get it working under certain versions of Red Hat Linux. I will use UCBLogo again in this article, but unlike then, UCBLogo logo is packaged and available under most of the major Linux distributions.
On Fedora:
> yum install ucblogo
On Ubuntu:
> apt-get install ucblogo
To start up the interpreter, just open up a terminal and run:
> logo
And the interpreter prompt will look something like this:
Welcome to Berkeley Logo version 5.6 ?
Now, UCBLogo has a "programmable" cursor that draws on the screen whatever you tell it to do. That cursor is known as the turtle, which in some other versions of Logo is an actual icon of a turtle instead of a triangular cursor. It's with our turtle that I try to captivate my kids' imagination. The following are some basic commands that will let your kids 'tell' the turtle what to do and, at the same time, learn concepts in programming, geometry and Boolean logic amongst others.
Tell the turtle to go forward 100 pixels with:
? fd 100
Tell the turtle to go backward 50 pixels with:
? bk 50
You can tell the turtle to turn:
? left 90
or even:
? right 270
Where 90 and 270 is how many degrees the turtle should turn given the right or left command. Can you visualize the introduction to angles right here? In my case, I tried to illustrate the concept of an angle to my kids by using something they are quite familiar with: roller skating. They knew what a '360' was when someone roller skates, but I don't think they knew what that number meant. So, I used Logo's turtle to illustrate to them what angles are all about.
These four basic commands will allow your kids to draw quite a few things, but something will be missing. It would be nice if your kids could use some colors to make their drawings a bit more fun, and also how to tell the turtle to 'walk' without drawing. Here's how we do it:
To turn off the turtle's ability to draw, so we can move it around the canvas without leaving a trace behind it:
? penup
Now, you will be able to go forward or backward without tracing. When you are done moving it, turn it back on with:
? pendown
In UCBLogo, at least on Fedora, you have 16 different colors to play with. You can change the background color and the turtle's pen color. The colors are identified by a number between 0 and 15.
To change the background color:
? setbg 2
To change the turtle's pen color:
? setpencolor 15
When you are all done, you can clear the turtle's canvas with:
? cs
In Logo, you can always use the help command to see what commands are available for the interpreter, and find documentation on each of them. The output of the help command looks like this:
? help Help is available on the following: * cursor keyp poall setlibloc + define label pon setmargins - definedp labelsize pons setpalette .defmacro dequeue last pop setpen .eq difference left popl setpencolor .macro do.until lessequalp popls setpenpattern .maybeoutput do.while lessp pops setpensize --- more ---
And to get specific help on a given command, you use:
? help "left LEFT degrees LT degrees turns the turtle counter clockwise by the specified angle, measured in degrees (1/360 of a circle).
Note: You will need to use the double quote (") in front of any command you would like some help on.
Another helpful resource to prepare you to use Logo to teach your kids is the official manual, which I find myself going back to every once in a while as a good reference as I come up with ideas for problems which my kids will help me solve.
The title of this article was somewhat long, so you may not have noticed the 'PART I' tagged at the end of the string. Next month, I intend to write the second (and final) part. I will share with you how to teach the turtle new words (i.e. write your own functions/procedures), how to do some basic conditional statements, loops, code management so you can save your work, and even some recursion.
Finally, let me end by saying that your kids may not understand some of the concepts you are trying to show them right away, but the older they get the more these concepts will start sinking in. Hopefully one day they will grow to appreciate programming and maybe even want to become a programmer themselves.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/silva.jpg)
Anderson Silva works as an IT Release Engineer at Red Hat, Inc. He holds a BS in Computer Science from Liberty University, a MS in Information Systems from the University of Maine. He is a Red Hat Certified Engineer, and has authored several Linux based articles for publications like: Linux Gazette, Revista do Linux, and Red Hat Magazine. Anderson has been married to his High School sweetheart for 11 years, and has 3 kids. When he is not working or writing, he enjoys spending time with his family, watching Formula 1 and Indycar races, and taking his boys karting.
My family's DSL hookup is in the kitchen, and we distribute Internet access around the house with a wireless router, but so far, we cannot listen to Internet radio in the kitchen. Of course, I could buy a commercial off-the-shelf Internet radio, but what is the fun in doing that? On the other hand, I could buy a Linux-based wireless router with USB, connect a USB sound card to it, and have fun making the whole enchilada work in a (moderately) user-friendly way, such that other members of the family can also use it. In order to make the project reasonably lightweight and manageable over a summer break I decided to avoid hardware modifications (as much fun as that may be) or the installation of large software packages like perl on the router. Almost all programming is done with shell scripts.
Before starting, I'd like to point out that listening to an Internet radio stream at 128 kbits/sec generates 1.4 GB of network traffic in a 24 hour period. You might want to keep this in mind, if you do not have a flat-rate plan, but have to pay proportionate to the volume of your Internet access. That being said, let's delve into implementation details, and start by discussing hardware.
I purchased what must have been the last available ASUS WL-500g Premium, with two USB2 connectors on the back. Any other router will probably work, if it has at least one USB port and can have its operating system (firmware) replaced by a Linux-based system that also supports USB. I chose OpenWRT [1] which is a Debian derivative for embedded appliances and comes with support and drivers for many gadgets, in particular the inexpensive no-name USB sound card that I bought. (The lsusb command reports 0d8c:000c C-Media Electronics, Inc. Audio Adapter.) In order to hear the music, I connected the sound card's output to some active speakers I had lying around. Standard headphones should also work, but I would refrain from using passive speakers, because the USB sound card receives power via the USB port, and larger passive speakers might load the USB port beyond tolerable levels.
Installing a new Linux-based operating system on the router is next: I follow the installation instructions for OpenWRT 8.09.1 (Kamikaze) [2] and re-flash the firmware of the router. I can then log on to the router for the first time. Immediately after flashing, the router has the default IP address 192.168.1.1, and I can connect a computer to one of the router's LAN ports. By default, the router has a DHCP server enabled, such that any computer requesting an IP via DHCP can connect. I then use telnet to log on to the router as user 'root'. No password is needed as long as the root password is not set with the 'passwd' command. Once it is set, one needs to use ssh for shell access. For testing and developing, I prefer shell access, but standard administrative tasks such as adjusting network settings or installing additional software can be more easily done with the LuCI Web-based interface, which can be reached by pointing your browser to the router, which still has IP address 192.168.1.1, unless you have changed it. You need to log on as user 'root' with the previously chosen password. You can now change all router settings and install additional drivers and software. To have full access to all configuration features, select 'Administration' mode, on the top right of LuCI's interface.
Before we can install more software, we need to connect the router to the Internet. This is helped by the router's WAN port being configured, by default, to request an IP from whatever it is connected to. I hooked up the ASUS's WAN port to one of the LAN ports on the old DSL router in our kitchen. In this way, the ASUS has access to the Internet, and can contact software repositories.
The initial OpenWRT installation does not support USB devices, we have to install drivers to enable the use of USB memory sticks and the USB sound card. In LuCI the software installation page can be found under the tab labelled 'System/Software'. First, update the package lists by selecting the top-left link on the Software page, which causes the page to be reloaded with a large number of available packages. Install packages by checking a box in the appropriate line, and pressing the 'Perform Actions' button at page bottom. There is a useful filter function available, which makes finding appropriate packages easy.
For USB memory stick support I follow Ref. [3] and install the kernel modules kmod-usb-uhci, kmod-usb-ohci, kmod-usb2 for generic USB1 and USB2 support. Since most USB memory sticks come with a FAT file system, I also install kmod-fs-vfat. When installing from the LuCI Web-interface, all relevant modules are already loaded, so no insmod commands are needed. The kernel-module required for the sound card is kmod-usb-audio, as described in Ref. [4].I also install the madplay mp3-player package. For debugging purposes, the usbutils package, which contains the lsusb command, is useful.
After installing all required packages, I finally log on to the router via ssh to get a command shell, and follow Ref. 4 to play an Internet radio station from the shell by entering
wget -q -O - https://94.23.29.150:11022 | madplay -
To my utter surprise, this worked the first time I tried — commendations to the OpenWRT developers. In the above command, wget pulls the mp3 radio stream from IP and port number https://94.23.29.150:11022 and pipes it to standard output, where madplay receives it and uses the default sound device /dev/dsp as output, where it is made audible on the speakers. Note that this constitutes the core of the Internet radio player. However, logging on to the router to start it is rather inconvenient. Moreover, there is only one useful button on the router, which makes building a user interface without direct computer access difficult. Further on, I describe my user interface to the Internet radio router.
A word about finding an Internet radio station's address is in order. I usually find stations by selecting them from https://www.shoutcast.com/ and playing in xmms on my desktop computer. In xmms, the 'view file info' selection in the file menu (or pressing CTRL-3) reveals the station's address.
The fact that only a single button is available for a user interface makes it necessary to contemplate what functionality is essential, and how often different activities happen. For example, turning the radio on or off, or switching between radio stations, will happen frequently and should be possible without an extra computer, by just using the single available button. Consequently, I will program the button to cycle between five pre-selected radio stations and 'OFF' as the sixth state. Selection of stations is aided by short sound files, stating the channel number, that are played before selection of a new station. Changing the pre-selected stations occurs much more rarely, and will use the Web server, including cgi-bin facilities, available on the router that normally serves the LuCI interface.
Let's start with programming the button. There are actually two buttons on the back of the router: one is red and protruded, and labelled 'EzSetup'. The another one is labeled 'Restore', and requires a pointed device such as a pen to activate. I will therefore use only the 'EzSetup' button. It turns out to be rather simple to do so. All the following activities are performed while ssh'd into the router and using the vi editor installed on it. The button is triggered asynchronously to other router activities, and is therefore under the control of a 'hotplug' daemon with configuration files under /etc/hotplug.d/. Under this directory, we first need to create subdirectory /etc/hotplug.d/button/, and, in this subdirectory, we create the script handler that is executed when a button is pressed. This functionality is also used to turn the wireless network on or off, as explained in Refs. [5] [6]. Specific information pertaining to the ASUS router can be found in Ref. [2].
Before discussing the script, we need to make its existence known to the system. All configuration information is stored in the subdirectory /etc/config/, where I create a file radio to hold all persistent information, surving any router reboots. My copy of that file is reproduced below:
# file: /etc/config/radio config 'radio' option 'button' 'ses' option 'state' '0' option 'ch1' 'https://216.155.137.150:10000' option 'ch2' 'https://scfire-dtc-aa07.stream.aol.com:80/stream/1075' option 'ch3' 'https://scfire-mtc-aa04.stream.aol.com:80/stream/1006' option 'ch4' 'https://94.23.17.224:8396' option 'ch5' 'https://94.23.29.150:11022'
The first non-comment line states the parameter name, here radio, followed by options. The most important one is the assigned button ses. I also added a state, used to keep track of the station just listened to, and also to tell which station is next. The parameters labeled chX store addresses of the pre-selected radio stations. On the command line or in scripts, parameters can be read using the uci command using the following construction uci get radio.@radio[0].state and written by uci set radio.@radio[0].state=3 , where we use the state variable in this example. The other parameters can be changed in a similar way. The program uci is a convenient interface on OpenWRT to access configuration parameters. It does, however, manipulate copies of the parameters only in memory, not on disc. Current parameters can be written to the configuration file using the command uci commit radio , which will again make the values persistent. This feature will be used to change the pre-selected radio stations.
Having made available the configuration variables that keep track of the current station and the station addresses, we can now discuss the action taken when the back-panel button is pressed. Remember, this is stored in file /etc/hotplug.d/button/handler. A fragment of the file is reproduced here:
#!/bin/sh # file: /etc/hotplug.d/button/handler # logger button handler: $BUTTON $ACTION $SEEN STATE=$(uci get radio.@radio[0].state) CH1=$(uci get radio.@radio[0].ch1) CH2=$(uci get radio.@radio[0].ch2) CH3=$(uci get radio.@radio[0].ch3) CH4=$(uci get radio.@radio[0].ch4) CH5=$(uci get radio.@radio[0].ch5) if [ $BUTTON = "ses" ] then if [ $ACTION = "released" ] then killall wget if [ $SEEN -gt "0" ] then STATE=-1 fi case $STATE in 0 ) madplay /root/radio/ch1.mp3 wget -q -O - $CH1 |\ madplay - & uci set radio.@radio[0].state=1 ;; 1 ) madplay /root/radio/ch2.mp3 wget -q -O - $CH2 |\ madplay - & uci set radio.@radio[0].state=2 ;; * ) uci set radio.@radio[0].state=0 madplay /root/radio/off.mp3 ;; esac fi fi
A complete copy is here. Pushing the router's back-panel button triggers execution of this file. The system also supplies three environment variables $BUTTON, $ACTION, and $SEEN at runtime. The variable $BUTTON can have the values ses or reset, depending whether one has pressed the red protruded EzSetup button or the other button. The variable $ACTION can have the values 'pressed' or 'released', depending on what happened to the button. Variable $SEEN contains the number of seconds since the last button event. We will use it to distinguish short versus long button presses. These variables will play a prominent role in the script that we will briefly describe now. At the top of the handler script the state variable is read, which keeps track of the station. It also assigns the station addresses to variables CHX. Then, we check that the EzSetup button named 'ses' has been activated; the following section runs only if the button is released. If we didn't check for either 'pressed' or 'released', the script would run twice, once when the button is pressed, and once when released. By checking the release event, we can distinguish between short and long button presses, because the $SEEN variable is reset to zero at both events. If $SEEN is zero, less than a second has elapsed between button pressed and released. Once inside the if statements, we kill any active wget process, since we can listen to only a single station at a time.
The associated madplay process also gets killed, because the parent process is gone. Then we check the $SEEN variable, and set the $STATE variable to a value that will cause the following case statement to reach a state that turns the radio off. The case statement itself is used to cycle through the stations: if the state is '0', it will start station 1, and so forth. In each case section, first a short mp3 sound file gets played to identify the station. On my desktop computer, I recorded myself saying 'Channel one', and converted the recording to a mp3 file named ch1.mp3 and copied the files via 'scp' to the router, but anything can go here. You could, for example, extract the jingle of the radio station and put it in a file. Playing this short identifier is just an aid to figuring out which radio station has been selected. This is followed by the construction with wget piped into madplay, discussed above, and the state variable gets incremented by one. I use five stations to cycle through, and the last section just tells me that the radio is off and does not receive data from the Internet.
The construction with the handler script provides basic functionality to step through a set of pre-selected radio stations, but changing these stations still requires logging on to the router and editing the configuration files by hand. We remedy that deficiency in the next section.
The router already sports a Web server to support the LuCI configuration interface. All served files are located under the directory /www/, and even cgi-bin functionality is supported if one places executables in directory /www/cgi-bin/. This means that we can use a Web browser to run programs on the router — cool, eh? Just make certain that the router is accessible only from a trusted network.
First, however, we have to prepare a Web page to tell us what the five current radio stations are. The following script excerpt does that.
#!/bin/sh
# file: /www/cgi-bin/radio.cgi
echo 'HTTP/1.0 200 OK'
echo 'Server: Netscape-Communications/3.0'
echo 'Content-type: text/html'
echo
ch1=$(uci get radio.@radio[0].ch1)
ch2=$(uci get radio.@radio[0].ch2)
ch3=$(uci get radio.@radio[0].ch3)
ch4=$(uci get radio.@radio[0].ch4)
ch5=$(uci get radio.@radio[0].ch5)
header='<HTML><HEAD><TITLE>Radio Channels</TITLE></HEAD><BODY>
<H1 ALIGN=CENTER>Radio channel selection</H1>'
echo $header
echo '<FORM action="setchannel.sh" method="get">'
echo -n 'Channel 1: <input type="text" name="ch1" size="80" value="'
echo -n $ch1; echo '"> '
echo '<input type="submit" value="Submit">'
echo '</FORM>'
:
echo '<FORM action="setchannel.sh" method="get">'
echo -n 'Channel 5: <input type="text" name="ch5" size="80" value="'
echo -n $ch5; echo '"> '
echo '<input type="submit" value="Submit">'
echo '</FORM>'
echo '<FORM action="commit.sh" method="get">'
echo '<input type="submit" value="Make persistent on Router">'
echo '</FORM>'
echo '</BODY></HTML>'
I just omitted a few copies of the five-line FORM statement for channel 2, 3, and 4, but the complete script is available here. The script must be made executable (chmod +x radio.cgi) and placed in /www/cgi-bin/. Pointing your desktop computer's Web browser to 192.168.1.1/cgi-bin/radio.cgi will show a Web page with five lines, where the radio stations are shown, and each line has a button on the right with 'Submit' written on it. (See screen shot, below.)
The idea is to change the radio station's address in the text area, and press the submit button to update the router's setting. Precisely that is part of the radio.cgi script's functionality. Note that the script gets executed under cgi-bin, which implies that all script output, normally written to standard output, must be redirected to the calling Web browser. In the script, all output therefore gets generated by an echo command. The first few lines prepare the standard header all Web browsers expect, and then variables chX get filled with the station addresses. Then, HTML header information gets defined and written by an echo command.
The next five lines define a form containing the text field with the station address, that is already filled with the current address. This is followed by the submit button definition. In the FORM definition's first line, the action="setchannel.sh" portion defines a program that must reside in the router's cgi-bin directory to receive the contents of the text field -- the station address -- if the submit button gets pressed. Please consult any book on HTML about how HTML forms and cgi-bin work in detail; for example, Ref. [7] or [8]. The final three-line FORM statement is used to execute the router's commit.sh script to make the variables persistent across router reboots.
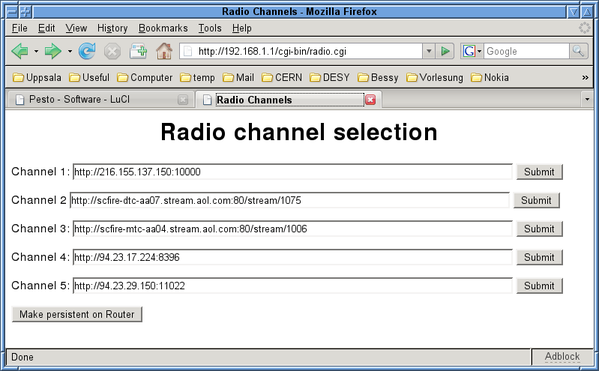
The receiving end of the main FORM construction is the setchannel.sh script, which must be made executable (chmod +x setchannel.sh) and likewise placed in /www/cgi-bin/. A copy is shown below:
#!/bin/sh
# file: /www/cgi-bin/setchannel.sh
decode(){
echo $QUERY_STRING |\
sed 's/+/ /g'| sed 's/\%0[dD]//g' |\
awk '/%/{while(match($0,/\%[0-9a-fA-F][0-9a-fA-F]/))\
{$0=substr($0,1,RSTART-1)sprintf("%c",0+("0x"substr(\
$0,RSTART+1,2)))substr($0,RSTART+3);}}{print}'
}
TMP=$( decode )
CHAN=${TMP%=http*}
URL=${TMP:4}
uci set radio.@radio[0].$CHAN=$URL
echo "Setting Channel $CHAN to station $URL"
A copy for download is available here. In this script we first define a function to undo the URL decoding imposed on the variables sent by the FORM in script radio.cgi. I adapted a script found at Ref. [9] to decode the QUERY_STRING and then a little shell scripting to extract the channel and URL. A final uci set command sets the variables on the router. Note that this sets radio station addresses only in the router's memory. In order to make them persistent, we need to execute a uci commit radio command using the commit.sh script, reproduced below:
#!/bin/sh
# file: /www/cgi-bin/commit.sh
uci set radio.@radio[0].state=0
uci commit radio
echo 'Channel selection made permanent on Router'
We see that it only initializes the state variable to the initial value zero, and then executes the commit script and echos what it did to the calling Web browser.
Using the presented interface, it is possible to change the desired radio stations' addresses, and make them persistent. Selecting one of the five stations, or turning the radio off, is then easily done by using the rear-panel red button. Our router is now permanently placed in the kitchen, and is used to play music from Internet radio stations.
Of course, a router with USB connectivity is a magnificent device for further activities. One could, for example, consider attaching a Bluetooth dongle (see Ref. [10]), and use a Bluetooth-capable cell 'phone to control radio station selection. I discuss how to do that on the 'phone in Ref. [11]. Including the Internet radio control features into the LuCI interface would also be a nice project. But you, dear reader, will certainly come up with other fun ways to use a marvelous box such as a router with USB.
[1] https://www.openwrt.org
[2] OpenWrtDocs/Hardware/Asus/WL500GP on page https://oldwiki.openwrt.org/TitleIndex.html
[3]
https://oldwiki.openwrt.org/UsbStorageHowto.html
[4]
https://oldwiki.openwrt.org/UsbAudioHowto.html
[5] OpenWrtDocs/Customizing/Software/WifiToggle on page
https://oldwiki.openwrt.org/TitleIndex.html
[6]
https://forum.openwrt.org/viewtopic.php?id=11565
[7] R. Darnell, et al., HTML4 Unleashed, SAMS Publishing, 1999.
[8] https://de.selfhtml.org/ (unfortunately only available in German)
[9] https://do.homeunix.org/UrlDecoding.html
[10]
https://forum.openwrt.org/viewtopic.php?id=1650
[11]
Desktop Bluetooth Remote, Linux Gazette 153, August 2008.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/ziemann.jpg)
Volker lives in Uppsala, Sweden and works as a physicist on particle accelerator based projects at CERN in Switzerland and DESY in Germany. He was forced into using computers during his undergraduate thesis in the mid-eighties and has used them with growing enthusiasm ever since. He is an active Linux user since 1995.
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/2002/note.png)
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
These images are scaled down to minimize horizontal scrolling.
All "Doomed to Obscurity" cartoons are at Pete Trbovich's site,
https://penguinpetes.com/Doomed_to_Obscurity/.
Talkback: Discuss this article with The Answer Gang
Born September 22, 1969, in Gardena, California, "Penguin" Pete Trbovich today resides in Iowa with his wife and children. Having worked various jobs in engineering-related fields, he has since "retired" from corporate life to start his second career. Currently he works as a freelance writer, graphics artist, and coder over the Internet. He describes this work as, "I sit at home and type, and checks mysteriously arrive in the mail."
He discovered Linux in 1998 - his first distro was Red Hat 5.0 - and has had very little time for other operating systems since. Starting out with his freelance business, he toyed with other blogs and websites until finally getting his own domain penguinpetes.com started in March of 2006, with a blog whose first post stated his motto: "If it isn't fun for me to write, it won't be fun to read."
The webcomic Doomed to Obscurity was launched New Year's Day, 2009, as a "New Year's surprise". He has since rigorously stuck to a posting schedule of "every odd-numbered calendar day", which allows him to keep a steady pace without tiring. The tagline for the webcomic states that it "gives the geek culture just what it deserves." But is it skewering everybody but the geek culture, or lampooning geek culture itself, or doing both by turns?
Once upon a time, when the Internet was young, most everything that happened was all about text. We interacted with words on a screen. No one really knew whether those words and thoughts came from the proverbial dog, axe-murderer, 13-year old girl, or the occasional net-savvy granny. Some of us are old enough to remember the shock and thrill of pictures attached to e-mail for the first time, or the giddyness of the nascent World Wide Web - "Hey, guess what company showed up on the Web?"
Sometimes it's hard to believe that we all lived without technology we take for granted in the present. It's an unusual company that has no Web-presence now. I find it amazing how ubiquitous and indispensable cellphones have become. I used to wonder why anyone needed text-messaging on their phone plan, and now I use it constantly, between querying Google for directory information and sending pictures of our kids off to Grandma, on the other side of the continent.
Linux Gazette has always been an evolving concept, from the very first issues written by John Fisk, to all the changes written up by Rick Moen in https://linuxgazette.net/issue96/moen.html. It's been available as a PalmDoc for quite a while now, as well as an RSS feed.
Recently, we've been talking about changing directions for LG; in today's world, those who don't change, and change fast enough, get left behind - and at Internet speeds, too. We held some discussions where some pretty radical ideas were floated, including some wild technical proposals. What made more sense, though, were the social approaches - going through our various contact lists to find more of the willing volunteers that have always made LG work, whether by finding entirely new faces or welcoming back veterans. Now that we're getting that ball rolling, it's clear that we've rejoined the front lines of net.culture, by jumping into the whirl of social networking.
Given all that, it's hardly surprising - although much appreciated - that one of the people who rejoined LG recently, Anderson Silva, started a Facebook group for Linux Gazette, with Ben's blessing. We're still working out all the initial details, but it's very likely to lead to as-yet unexpected and unenvisioned connections. Come join us at https://www.facebook.com/group.php?gid=110960368283&ref=nf!
Meanwhile, special thanks are due to Suramya Tomar, who brought Pete Trbovich's "Doomed to Obscurity" trenchantly funny cartoons to our attention, and Steve Brown, who's been doing amazing work getting current and former LG staff and authors re-energized. Joey Prestia has been inspiring his talented friends to contribute, and we're slowly getting more and more volunteers pitching in to edit at publication time, as well.
As always, LG needs more people - so if you can spare some time to help the community, we'd love to have you! You can start by taking a look at our jobs page; if you notice something clever that can be done that we've forgotten to ask for, do let us know.
Maybe you don't have time to give to LG yourself, but you might know someone else who would make a great addition to LG. Or maybe someone you know knows someone else who...? Spread the word!
Talkback: Discuss this article with The Answer Gang

Kat likes to tell people she's one of the youngest people to have learned to program using punchcards on a mainframe (back in '83); but the truth is that since then, despite many hours in front of various computer screens, she's a computer user rather than a computer programmer.
Her transition away from other OSes started with the design of a massively multilingual wedding invitation.
When away from the keyboard, her hands have been found wielding of knitting needles, various pens, henna, red-hot welding tools, upholsterer's shears, and a pneumatic scaler. More often these days, she's occupied with managing her latest project.

![[cartoon]](misc/xkcd/tech_support_cheat_sheet.png "'Hey Megan, it's your father. How do I print out a flowchart?'")
