
Using Hyperestraier to search your stuff
By Karl Vogel
1. Introduction
I have files, mail, and source code on my system going clear back to 1993. I've tried WAIS, Glimpse, SWISH, and one or two home-grown systems to index it for searching, but so far QDBM and Hyperestraier have given the best results.
2. Setting up QDBM
QDBM is a key/value database, similar to the DBM and NDBM libraries commonly found on most Unix-type systems. It's the underlying DB used by Hyperestraier. Installing it was a breeze; instructions are at https://qdbm.sourceforge.net/spex.html.
[ Modern Linux distributions have either all or most of the software discussed in this article available as standard packages, so installing them is a matter of simply selecting them in your package manager. In Debian, for example, you'd simply type "apt-get install qdbm-utils hyperestraier" at the command line. However, as always, it's good to know the fallback route - which is the download/decompress/compile/install cycle shown here. -- Ben ]
If you're impatient, the installation steps are:
me% wget https://qdbm.sourceforge.net/qdbm-1.8.77.tar.gz me% gunzip -c qdbm-1.8.77.tar.gz | tar xf - me% cd ./qdbm-1.8.77 me% CC=gcc CFLAGS=-O ./configure --enable-zlib --enable-iconv me% make me% make check root# make install root# rm /usr/local/share/qdbm/spex-ja.html me% make distclean
The software makes extensive use of compression; it handles several libraries, but zlib is probably the most common, so that's the one I used.
2.1. Configure
Here's how I configured it for use under Solaris. The FreeBSD and Linux steps aren't significantly different:
me% CC=gcc CFLAGS=-O ./configure --enable-zlib --enable-iconv #================================================================ # Configuring QDBM version 1.8.77 (zlib) (iconv). #================================================================ checking for gcc... gcc checking for C compiler default output file name... a.out checking whether the C compiler works... yes checking whether we are cross compiling... no checking for suffix of executables... checking for suffix of object files... o checking whether we are using the GNU C compiler... yes checking whether gcc accepts -g... yes checking for gcc option to accept ANSI C... none needed checking for ld... /usr/ccs/bin/ld checking for ar... /usr/ccs/bin/ar checking for main in -lc... yes checking for main in -lz... yes checking for main in -liconv... no checking for main in -lqdbm... no configure: creating ./config.status config.status: creating Makefile config.status: creating LTmakefile config.status: creating qdbm.spec config.status: creating qdbm.pc
2.2. Build and test
Run make as usual. I abbreviated the compile, load, and library lines to shorten the output:
$compile = gcc -c -I. -I/usr/local/include \
-DMYZLIB -DMYICONV -D_XOPEN_SOURCE_EXTENDED=1 \
-D_GNU_SOURCE=1 -D__EXTENSIONS__=1 -D_HPUX_SOURCE=1 \
-D_POSIX_MAPPED_FILES=1 -D_POSIX_SYNCHRONIZED_IO=1 -DPIC=1 \
-D_THREAD_SAFE=1 -D_REENTRANT=1 -DNDEBUG -Wall -pedantic -fPIC \
-fsigned-char -O3 -fomit-frame-pointer -fforce-addr -O1 \
-fno-omit-frame-pointer -fno-force-addr
$load = LD_RUN_PATH=/lib:/usr/lib:/usr/local/lib: \
gcc -Wall -pedantic -fPIC -fsigned-char -O3 -fomit-frame-pointer \
-fforce-addr -O1 -fno-omit-frame-pointer -fno-force-addr
$ldflags = -L. -L/usr/local/lib -lqdbm -lz -lc
Here's the build:
me% make
$compile depot.c
$compile curia.c
$compile relic.c
$compile hovel.c
$compile cabin.c
$compile villa.c
$compile vista.c
$compile odeum.c
$compile myconf.c
/usr/ccs/bin/ar rcsv libqdbm.a depot.o curia.o relic.o hovel.o cabin.o \
villa.o vista.o odeum.o myconf.o
a - depot.o
a - curia.o
a - relic.o
a - hovel.o
a - cabin.o
a - villa.o
a - vista.o
a - odeum.o
a - myconf.o
ar: writing libqdbm.a
if uname -a | egrep -i 'SunOS' > /dev/null ; \
then \
gcc -shared -Wl,-G,-h,libqdbm.so.14 -o libqdbm.so.14.13.0 depot.o curia.o \
relic.o hovel.o cabin.o villa.o vista.o odeum.o myconf.o -L. \
-L/usr/local/lib -lz -lc ; \
else \
gcc -shared -Wl,-soname,libqdbm.so.14 -o libqdbm.so.14.13.0 depot.o \
curia.o relic.o hovel.o cabin.o villa.o vista.o odeum.o myconf.o -L. \
-L/usr/local/lib -lz -lc ; \
fi
ln -f -s libqdbm.so.14.13.0 libqdbm.so.14
ln -f -s libqdbm.so.14.13.0 libqdbm.so
$compile dpmgr.c
$load -o dpmgr dpmgr.o $ldflags
$compile dptest.c
$load -o dptest dptest.o $ldflags
$compile dptsv.c
$load -o dptsv dptsv.o $ldflags
$compile crmgr.c
$load -o crmgr crmgr.o $ldflags
$compile crtest.c
$load -o crtest crtest.o $ldflags
$compile crtsv.c
$load -o crtsv crtsv.o $ldflags
$compile rlmgr.c
$load -o rlmgr rlmgr.o $ldflags
$compile rltest.c
$load -o rltest rltest.o $ldflags
$compile hvmgr.c
$load -o hvmgr hvmgr.o $ldflags
$compile hvtest.c
$load -o hvtest hvtest.o $ldflags
$compile cbtest.c
$load -o cbtest cbtest.o $ldflags
$compile cbcodec.c
$load -o cbcodec cbcodec.o $ldflags
$compile vlmgr.c
$load -o vlmgr vlmgr.o $ldflags
$compile vltest.c
$load -o vltest vltest.o $ldflags
$compile vltsv.c
$load -o vltsv vltsv.o $ldflags
$compile odmgr.c
$load -o odmgr odmgr.o $ldflags
$compile odtest.c
$load -o odtest odtest.o $ldflags
$compile odidx.c
$load -o odidx odidx.o $ldflags
$compile qmttest.c
$load -o qmttest qmttest.o $ldflags
#================================================================
# Ready to install.
#================================================================
You can run make check to test everything, but the output is pretty long, and it takes awhile.
2.3. Install
Here's the installation, with long lines wrapped and indented:
root# make install
mkdir -p /usr/local/include
cd . && cp -Rf depot.h curia.h relic.h hovel.h cabin.h villa.h
vista.h odeum.h /usr/local/include
mkdir -p /usr/local/lib
cp -Rf libqdbm.a libqdbm.so.12.10.0 libqdbm.so.12 libqdbm.so
/usr/local/lib
mkdir -p /usr/local/bin
cp -Rf dpmgr dptest dptsv crmgr crtest crtsv rlmgr rltest hvmgr
hvtest cbtest cbcodec vlmgr vltest vltsv odmgr odtest odidx
/usr/local/bin
mkdir -p /usr/local/man/man1
cd ./man && cp -Rf dpmgr.1 dptest.1 dptsv.1 crmgr.1 crtest.1
crtsv.1 rlmgr.1 rltest.1 hvmgr.1 hvtest.1 cbtest.1 cbcodec.1
vlmgr.1 vltest.1 vltsv.1 odmgr.1 odtest.1 odidx.1
/usr/local/man/man1
mkdir -p /usr/local/man/man3
cd ./man && cp -Rf qdbm.3 depot.3 dpopen.3 curia.3 cropen.3
relic.3 hovel.3 cabin.3 villa.3 vlopen.3 vista.3 odeum.3
odopen.3 /usr/local/man/man3
mkdir -p /usr/local/share/qdbm
cd . && cp -Rf spex.html spex-ja.html COPYING ChangeLog NEWS
THANKS /usr/local/share/qdbm
mkdir -p /usr/local/lib/pkgconfig
cd . && cp -Rf qdbm.pc /usr/local/lib/pkgconfig
#================================================================
# Thanks for using QDBM.
#================================================================
Here's the list of installed files.
2.4. Command-line trials
If you want a feel for the DB command-line interface, you can create a QDBM file using /etc/passwd. Use a tab as the password-file field separator:
me% tr ':' '\t' < passwd | dptsv import casket me% ls -lF -rw-r--r-- 1 bin bin 111510 Apr 22 18:59 casket -r--r--r-- 1 bin bin 56858 Apr 22 18:59 passwd
Check and optimize the DB:
me% dpmgr inform casket name: casket file size: 111510 all buckets: 8191 used buckets: 799 records: 840 inode number: 184027 modified time: 1145746799 me% dpmgr optimize casket me% dpmgr inform casket name: casket file size: 107264 all buckets: 3583 used buckets: 768 records: 840 inode number: 184027 modified time: 1145746970 me% ls -lF casket -rw-r--r-- 1 bin bin 107264 Apr 22 19:02 casket
Now, try a simple search:
me% dpmgr get casket vogelke x 100 100 Karl Vogel /home/me /bin/sh me% dpmgr get casket nosuch dpmgr: casket: no item found
3. Setting up Hyperestraier
Hyperestraier can be downloaded from https://hyperestraier.sourceforge.net. If you're impatient, here's the Cliff-notes version of the installation. I'm assuming that your CGI scripts live under /web/cgi-bin:
me% wget https://hyperestraier.sourceforge.net/hyperestraier-1.4.13.tar.gz me% gunzip -c hyperestraier-1.4.13.tar.gz | tar xf - me% cd ./hyperestraier-1.4.13 me% CC=gcc CFLAGS=-O ./configure me% make me% make check root# make install root# mv /usr/local/libexec/estseek.cgi /web/cgi-bin root# cd /usr/local/share/hyperestraier/doc root# rm index.ja.html intro-ja.html nguide-ja.html root# rm cguide-ja.html pguide-ja.html uguide-ja.html me% make distclean
3.1. Configure
Here's the configuration for Solaris:
me% CC=gcc CFLAGS=-O ./configure #================================================================ # Configuring Hyper Estraier version 1.4.13. #================================================================ checking for gcc... gcc checking for C compiler default output file name... a.out checking whether the C compiler works... yes checking whether we are cross compiling... no checking for suffix of executables... checking for suffix of object files... o checking whether we are using the GNU C compiler... yes checking whether gcc accepts -g... yes checking for gcc option to accept ANSI C... none needed checking for main in -lc... yes checking for main in -lm... yes checking for main in -lregex... no checking for main in -liconv... no checking for main in -lz... yes checking for main in -lqdbm... yes checking for main in -lpthread... yes checking for main in -lnsl... yes checking for main in -lsocket... yes checking for main in -lresolv... yes checking the version of QDBM ... ok (1.8.77) configure: creating ./config.status config.status: creating Makefile config.status: creating estconfig config.status: creating hyperestraier.pc #================================================================ # Ready to make. #================================================================
3.2. Build, test, and install
Run make. I abbreviated the compile, load, and library lines like before to shorten the output.
Running the testbed took about 4 minutes on a 2.6 GHz workstation using Solaris-10.
4. Indexing and searching
You need two things for searching: a bunch of documents to look through and an inverted index. An inverted index contains words (as keys) mapped to the documents in which they appear. The index is sorted by the keys. "Inverted" means that the documents are the data which you find by looking for matching keys (words), instead of using the document as a key and getting back a bunch of words as the data (which is basically what the filesystem does).
4.1. Plain files
Here's one way to index a specific set of documents and search them from the command line.
I keep things like installation records in plain-text files named "LOG". They're all over the place, so I created an index just for them:
me% cd /search/estraier/logs me% ls -lF -rwxr-xr-x 1 bin bin 827 Nov 11 20:53 build* drwxr-xr-x 6 bin bin 512 Nov 12 04:08 srch/ me% ls -lF srch drwxr-xr-x 5 bin bin 512 Jan 8 2008 _attr/ -rw-r--r-- 1 bin bin 846611 Nov 12 04:08 _aux -rw-r--r-- 1 bin bin 621845 Nov 12 04:08 _fwm drwxr-xr-x 2 bin bin 512 Nov 12 04:07 _idx/ drwxr-xr-x 5 bin bin 512 Jan 8 2008 _kwd/ -rw-r--r-- 1 bin bin 68955 Nov 12 04:08 _list -rw-r--r-- 1 bin bin 282 Nov 12 04:08 _meta drwxr-xr-x 9 bin bin 512 Jan 8 2008 _text/ -rw-r--r-- 1 bin bin 192802 Nov 12 04:08 _xfm
The srch directory holds the inverted index. The build script is run nightly:
1 #!/bin/ksh 2 # 3 # Index my LOG-files. 4 # 5 # "-cm" is to ignore files which are not modified. 6 # "-cl" is to clean up data of overwritten documents. 7 test -f /search/estraier/SETUP && . /search/estraier/SETUP 8 logmsg start 9 if test -d "$dbname"; then 10 opts='-cl -sd -ft -cm' 11 else 12 opts='-sd -ft' 13 fi 14 locate /LOG | grep -v /archive/old-logfiles/ | grep '/LOG$' > $flist 15 test -s "$flist" || cleanup no LOG files found, exiting 16 estcmd gather $opts $dbname - < $flist 17 estcmd extkeys $dbname 18 estcmd optimize $dbname 19 estcmd purge -cl $dbname 20 cleanup
Here's a line-by-line description of the script:
- 7 test -f /search/estraier/SETUP && . /search/estraier/SETUP
- Set commonly-used variables
- 8 logmsg start
-
Write a message to the system log that looks like this:
Oct 27 04:06:55 hostname build-logs: start
- 9-13 if test -d "$dbname" ...
- If the index directory already exists, append to an existing index, otherwise create a brand-new index
- 14 locate /LOG | grep -v /archive/old-logfiles/ | grep '/LOG$' > $flist
- Find all files with a basename of LOG on the system, and exclude crufty old logfiles I don't care about.
- 15 test -s "$flist" || cleanup no LOG files found, exiting
- If there aren't any logfiles, write something to the system log, clean up any work files, and exit
- 16 estcmd gather $opts $dbname - < $flist
- Pass the logfiles found to the indexer
- 17 estcmd extkeys $dbname
- Create a database of keywords extracted from documents
- 18 estcmd optimize $dbname
- Optimize the index and clean up dispensable regions
- 19 estcmd purge -cl $dbname
- Purge anything about files which no longer exist
- 20 cleanup
- Write an ending message to the system log, clean up, and exit
Options used to generate the inverted index are covered in the "estcmd" manual page:
- -cl: regions of overwritten documents are cleaned up.
- -cm: ignore files which have not been modified.
- -ft: target files are treated as plain text.
- -sd: modification date of each file is recorded as an attribute.
I'll go through searching this index later.
I use slightly different versions of this script to index all sorts of things, so common code is all in the "SETUP" file:
1 # Common environment variables and settings.
2 #
3 # /usr/local/share/hyperestraier/filter must be included in
4 # the PATH if you're going to use external filters to extract keywords
5 # from any documents.
6 PATH=/usr/local/bin:/opt/sfw/bin:/bin:/sbin:/usr/sbin:/usr/bin
7 PATH=$PATH:/usr/local/share/hyperestraier/filter
8 export PATH
9 umask 022
10 # Syslog tag and starting directory
11 cwd=`pwd`
12 b=`basename $cwd`
13 tag="`basename $0`-$b"
14 unset b
15 # Search db to be created or updated
16 dbname=srch
17 # Scratch files
18 tmp="$tag.tmp.$$"
19 flist="$tag.flist.$$"
20 # die: prints an optional argument to stderr and exits.
21 # A common use for "die" is with a test:
22 # test -f /etc/passwd || die "no passwd file"
23 # This works in subshells and loops, but may not exit with
24 # a code other than 0.
25 die () {
26 echo "$tag: error: $*" 1>&2
27 exit 1
28 }
29 # logmsg: prints a message to the system log.
30 # expects variable "$tag" to hold the program basename.
31 #
32 # If CALLER environment variable is set, this is being run from cron;
33 # write to the system log. Otherwise write to stdout.
34 logmsg () {
35 case "$CALLER" in
36 "") date "+%Y-%m-%d %H:%M:%S $tag: $*" ;;
37 *) logger -t $tag "$*" ;;
38 esac
39 }
40 # cleanup: remove work files and exit.
41 cleanup () {
42 case "$#" in
43 0) logmsg done ;;
44 *) logmsg "$*" ;;
45 esac
46 test -f $flist && rm $flist
47 test -f $tmp && rm $tmp
48 exit 0
49 }
4.2. Web interface
Hyperestraier also provides a CGI program to handle browser searches. Let's say you want to search all the .htm files on your workstation. If your document root is /web/docs, here's how you could index it:
me% cd /search/estraier/web me% ls -lF -rwxr-xr-x 1 bin bin 991 Jan 12 2008 build* drwxr-xr-x 6 bin bin 512 Oct 27 05:38 srch/ me% % ls -lF srch drwxr-xr-x 5 bin bin 512 Jan 13 2008 _attr/ -rw-r--r-- 1 bin bin 4630443 Oct 27 05:38 _aux -rw-r--r-- 1 bin bin 1824281 Oct 27 05:38 _fwm drwxr-xr-x 2 bin bin 512 Oct 27 05:36 _idx/ drwxr-xr-x 5 bin bin 512 Jan 13 2008 _kwd/ -rw-r--r-- 1 bin bin 414384 Oct 27 05:38 _list -rw-r--r-- 1 bin bin 284 Oct 27 05:38 _meta drwxr-xr-x 9 bin bin 512 Jan 13 2008 _text/ -rw-r--r-- 1 bin bin 611407 Oct 27 05:38 _xfm me% nl build 1 #!/bin/ksh 2 # 3 # Index my web files. 4 # 5 # "-cm" is to ignore files which are not modified. 6 # "-cl" is to clean up data of overwritten documents. 7 test -f /search/estraier/SETUP && . /search/estraier/SETUP 8 logmsg start 9 dir=/web/docs 10 text='-ft' 11 html='-fh' 12 # If the search directory exists, then update it with 13 # recently-modified files. 14 if test -d "$dbname"; then 15 opts='-cl -sd -cm' 16 findopt="-newer $dbname/_fwm" 17 else 18 opts='-sd' 19 findopt= 20 fi 21 # Get a list of all text files under my webpage. 22 gfind $dir -type f $findopt -print0 > $flist 23 if test -s "$flist" 24 then 25 gxargs -0 file -N < $flist | grep ": .* text" > $tmp 26 else 27 cleanup nothing to do, exiting 28 fi 29 # Index non-HTML files as text, and HTML files as (surprise) HTML. 30 grep -v 'HTML document text' $tmp | 31 sed -e 's/: .* text.*//' | 32 estcmd gather $opts $text $dbname - 33 grep 'HTML document text' $tmp | 34 sed -e 's/: .* text.*//' | 35 estcmd gather $opts $html $dbname - 36 estcmd extkeys $dbname 37 estcmd optimize $dbname 38 estcmd purge -cl $dbname 39 cleanup
Here's a line-by-line description of the script. I'm assuming you use the GNU versions of "find" and "xargs", and a reasonably recent version of "file" that understands the "-N" (no padding of filenames to align them) option.
- 9 dir=/web/docs
- Set the directory we're going to index
- 10 text='-ft'
- Option for indexing plain-text files
- 11 html='-fh'
- Option for indexing html files
- 14-20 if test -d "$dbname" ...
- If the search directory exists, we're appending to the index. Look for files newer than "_fwm" file in the index directory. Otherwise, we're creating a new index, and find doesn't need any additional options
- 22 gfind $dir -type f $findopt -print0 > $flist
- List all regular files under the document root, and use the null character as a record separator instead of a newline in case we have spaces or other foolishness in the filenames.
- 23-28 if test -s "$flist" ...
- If we find any regular files, run "file" on each one, and keep only the ones that are some type of text. Otherwise print a message and bail out.
- 30 grep -v 'HTML document text' $tmp |
- Look for anything that's not HTML in the "file" output,
- 31 sed -e 's/: .* text.*//' |
- keep just the filename,
- 32 estcmd gather $opts $text $dbname -
- and pass it to the indexer with a filetype of text
- 33 grep 'HTML document text' $tmp |
- Look for anything that is HTML in the "file" output,
- 34 sed -e 's/: .* text.*//' |
- keep just the filename,
- 35 estcmd gather $opts $html $dbname -
- and pass it to the indexer with a filetype of html
- 36 estcmd extkeys $dbname
- Create a database of keywords extracted from documents
- 37 estcmd optimize $dbname
- Optimize the index and clean up dispensable regions
- 38 estcmd purge -cl $dbname
- Purge anything about files which no longer exist
- 39 cleanup
- Clean up and exit.
You need one more thing before your web search is ready: configuration files showing Hyperestraier how to change a URL into a filename, how to display results, what type of help to provide, and where the index is. Put these files wherever your CGI stuff lives:
-rwxr-xr-x 1 bin bin 67912 Jan 4 2008 /web/cgi-bin/estseek* -rw-r--r-- 1 bin bin 1300 Sep 5 2007 /web/cgi-bin/estseek.conf -rw-r--r-- 1 bin bin 5235 Jan 11 2007 /web/cgi-bin/estseek.help -rw-r--r-- 1 bin bin 6700 Jan 11 2007 /web/cgi-bin/estseek.tmpl -rw-r--r-- 1 bin bin 1961 Aug 8 2007 /web/cgi-bin/estseek.top
Here's the estseek.conf file for my workstation webpage:
1 #----------------------------------------------------------------
2 # Configurations for estseek.cgi and estserver
3 #----------------------------------------------------------------
4 # path of the database
5 indexname: /search/estraier/web/srch
6 # path of the template file
7 tmplfile: estseek.tmpl
8 # path of the top page file
9 topfile: estseek.top
10 # help file
11 helpfile: estseek.help
12 # expressions to replace the URI of each document (delimited with space)
13 replace: ^file:///web/docs/{{!}}https://example.com/
14 replace: /index\.html?${{!}}/
15 replace: /index\.htm?${{!}}/
16 # LOCAL ADDITIONS from previous version
17 lockindex: true
18 pseudoindex:
19 showlreal: false
20 deftitle: Hyper Estraier: a full-text search system for communities
21 formtype: normal
22 #perpage: 10 100 10
23 perpage: 10,20,30,40,50,100
24 attrselect: false
25 attrwidth: 80
26 showscore: true
27 extattr: author|Author
28 extattr: from|From
29 extattr: to|To
30 extattr: cc|Cc
31 extattr: date|Date
32 snipwwidth: 480
33 sniphwidth: 96
34 snipawidth: 96
35 condgstep: 2
36 dotfidf: true
37 scancheck: 3
38 phraseform: 2
39 dispproxy:
40 candetail: true
41 candir: false
42 auxmin: 32
43 smlrvnum: 32
44 smlrtune: 16 1024 4096
45 clipview: 2
46 clipweight: none
47 relkeynum: 0
48 spcache:
49 wildmax: 256
50 qxpndcmd:
51 logfile:
52 logformat: {time}\t{REMOTE_ADDR}:{REMOTE_PORT}\t{cond}\t{hnum}\n
53 # END OF FILE
You only need to change lines 5 and 13.
- 5 indexname: /search/estraier/web/srch
- Where to find the inverted index.
- 7, 9, 11
- Templates for displaying help and search results.
- 13 replace: ^file:///web/docs/{{!}}https: //example.com/
- How to translate search results from a pathname (/web/docs/xyz) to a URL.
Here's a screenshot of a search for "nanoblogger":
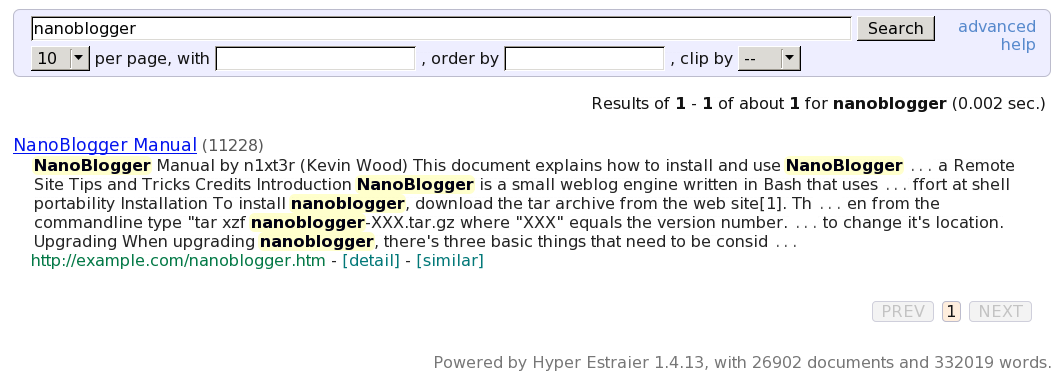
Notice the time needed (0.002 sec) to search nearly 27,000 documents.
The "detail" link at the bottom of each hit will display file modification time, size, etc. The "similar" link will search for any files similar to this one.
4.3. Indexing all your files
I run this script nightly to make or update indexes for all my document collections.
1 #!/bin/ksh
2 # Re-index any folders containing an executable "build" script.
3 PATH=/usr/local/bin:/bin:/sbin:/usr/sbin:/usr/bin
4 export PATH
5 umask 022
6 tag=`basename $0`
7 CALLER=$tag # used by called scripts
8 export CALLER
9 top="/search/estraier"
10 logfile="$top/BUILDLOG"
11 die () {
12 echo "$@" >& 2
13 exit 1
14 }
15 logmsg () {
16 ( echo; echo "`date`: $@" ) >> $logfile
17 }
18 # Update the index for each group of files.
19 # Skip any group with a "stop" file.
20 cd $top || die "cannot cd to $top"
21 test -f $logfile && rm $logfile
22 cp /dev/null README
23 for topic in *
24 do
25 if test -d "$topic" -a -x "$topic/build"
26 then
27 if test -f "$topic/stop"
28 then
29 logmsg skipping $topic
30 else
31 logmsg starting $topic
32 ( cd $topic && ./build 2>&1 ) >> $logfile
33 ( echo "`date`: $topic"
34 test -d $topic/srch && estcmd inform $topic/srch
35 echo ) >> README
36 fi
37 fi
38 done
39 logmsg DONE
40 # Clean up and link the logfile.
41 sedscr='
42 /passed .old document./d
43 /: passed$/d
44 /filling the key cache/d
45 /cleaning dispensable/d
46 s/^estcmd: INFO:/ estcmd: INFO:/
47 '
48 sed -e "$sedscr" $logfile > $logfile.n && mv $logfile.n $logfile
49 dest=`date "+OLD/%Y/%m%d"`
50 ln $logfile $top/$dest || die "ln $logfile $top/$dest failed"
51 exit 0
- 7 CALLER=$tag
- Used by any called scripts to send output to syslog.
- 23-39
- Looks for any directory beneath /search/estraier that holds a build script, runs each script in turn, logs the results, and creates a summary of indexed documents.
- 41-48
- Cleans up the build log.
- 49,50
-
Keeps old buildlogs for comparison, linking to the most recent one:
+-----OLD | +-----2008 | | ... | | +-----1111 | | +-----1112 | | +-----1113 | | +-----1114 [linked to the buildlog created on 14 Nov]
Here's part of the summary:
Fri Nov 14 04:07:48 EST 2008: home number of documents: 16809 number of words: 577110 number of keywords: 87211 file size: 116883727 inode number: 139 attribute indexes: known options: Fri Nov 14 04:08:38 EST 2008: logs number of documents: 3229 number of words: 110521 number of keywords: 21896 file size: 19354219 inode number: 10 attribute indexes: known options: [...]
Here's the script to search any (or all) document collections for a string:
1 #!/bin/ksh
2 #
3 # NAME:
4 # srch
5 #
6 # SYNOPSIS:
7 # srch [-ev] [-cfhlmnrstuw] pattern
8 #
9 # DESCRIPTION:
10 # Look through all Estraier DBs for "pattern".
11 # Default behavior (no options) is to search all DBs.
12 #
13 # OPTIONS:
14 # -e exact phrase search: don't insert AND between words
15 # -v print the version and exit
16 #
17 # -c search source-code index
18 # -f search index of mail headers received FROM people
19 # -h search home index
20 # -l search logs index
21 # -m search mail-unread index
22 # -n search notebook index
23 # -p search PDF index
24 # -r search root index
25 # -s search mail-saved index
26 # -t search index of mail headers sent TO people
27 # -u search usr index
28 # -w search web index
29 #
30 # AUTHOR:
31 # Karl Vogel <vogelke@pobox.com>
32 # Sumaria Systems, Inc.
33 . /usr/local/lib/ksh/path.ksh
34 . /usr/local/lib/ksh/die.ksh
35 . /usr/local/lib/ksh/usage.ksh
36 . /usr/local/lib/ksh/version.ksh
37 # List just the folders in a directory.
38 folders () {
39 dir=$1
40 ls -l $dir | grep '^d' | awk '{print $9}' | grep -v '[A-Z]'
41 }
42 # Command-line options.
43 sect=
44 exact='no'
45 while getopts ":echlmnprstuvw" opt; do
46 case $opt in
47 c) sect="$sect src" ;;
48 e) exact='yes' ;;
49 h) sect="$sect home" ;;
50 l) sect="$sect logs" ;;
51 m) sect="$sect mail-unread" ;;
52 n) sect="$sect notebook" ;;
53 p) sect="$sect pdf" ;;
54 r) sect="$sect root" ;;
55 s) sect="$sect mail-saved" ;;
56 t) sect="$sect sent" ;;
57 u) sect="$sect usr" ;;
58 w) sect="$sect web" ;;
59 v) version; exit 0 ;;
60 \?) usage "-$OPTARG: invalid option"; exit 1 ;;
61 esac
62 done
63 shift $(($OPTIND - 1))
64 # Sanity checks.
65 top='/search/estraier'
66 test -d "$top" || die "$top: not found"
67 # If exact search specified, search for that phrase.
68 # If not, create search pattern: "word1 AND word2 AND word3 ..."
69 # Run the search, 40 hits maximum.
70 # Ignore password-checker stuff; that holds dictionaries.
71 case "$@" in
72 "") usage "no pattern to search for" ;;
73 *) ;;
74 esac
75 case "$exact" in
76 yes) pattern="$@" ;;
77 no) pattern=`echo $@ | sed -e 's/ / AND /g'` ;;
78 esac
79 echo "Searching for: $pattern"
80 # Top-level directories are sections.
81 case "$sect" in
82 "") sect=`folders $top` ;;
83 *) ;;
84 esac
85 for db in $sect; do
86 if test -d "$top/$db/srch"; then
87 echo
88 echo "=== $db"
89 estcmd search -vu -max 40 $top/$db/srch "$pattern" |
90 grep -v /src/security/password-checker/ |
91 grep 'file://' |
92 sed -e 's!^.*file://! !'
93 fi
94 done
95 exit 0
There isn't too much new in this script:
- 33-36
- Keeps commonly-used functions from cluttering things up. In particular, usage.ksh displays the comment header as a help message in case the user botches the command line.
- 89 estcmd search -vu -max 40 $top/$db/srch "$pattern" |
- Does the actual search, displaying a maximum of 40 results as URLs.
- 90 grep -v /src/security/password-checker/ |
- Keeps password-cracking dictionaries from showing a hit for just about everything.
Here's what a basic search looks like:
me% srch hosehead Searching for: hosehead === home /home/me/mail/replies/apache-redirect === logs /src/www/sysutils/LOG === mail-saved === mail-unread === notebook /home/me/notebook/2005/0701/console-based-blogging === pdf === root === sent === src /src/opt/rep/RCS/sample%2Cv === usr === web
Results are URL-ified, so files containing special characters like commas will have them escaped:
/src/opt/rep/RCS/sample,v ==> /src/opt/rep/RCS/sample%2Cv
4.4. Using attributes
One of the nicer features of Hyperestraier is the ability to "dump" an inverted index in a way that lets you see exactly how any one source document contributes to the index as a whole. You can see how words are weighted, and better yet, you can create similar files with additional information and use them to create the index.
The files dumped from an inverted index are referred to as "draft files", and they have an extension of ".est". Here's a sample index of two documents:
me% cd /tmp/websearch
me% ls -lF doc*
-rw-r--r-- 1 bin bin 186 Oct 28 19:42 doc1
-rw-r--r-- 1 bin bin 143 Oct 28 19:42 doc2
me% cat -n doc1
1 One of the nicer features of Hyperestraier is the ability to "dump"
2 an inverted index in a way that lets you see exactly how any one
3 source document contributes to the index as a whole.
me% cat -n doc2
1 You can see how words are weighted, and better yet, you can create
2 similar files with additional information and use them to create
3 the index.
me% ls doc* | estcmd gather -sd -ft srch -
estcmd: INFO: reading list from the standard input ...
estcmd: INFO: 1 (doc1): registered
estcmd: INFO: 2 (doc2): registered
estcmd: INFO: finished successfully: elapsed time: 0h 0m 1s
Now, let's look at the internal (draft) documents that Hyperestraier actually uses. First, list all the documents in the index:
me% estcmd list srch 1 file:///tmp/websearch/doc1 2 file:///tmp/websearch/doc2
Here are the drafts:
me% estcmd get srch 1 > doc1.est me% estcmd get srch 2 > doc2.est me% cat doc1.est @digest=ebc6fbd6e5d2f6d399a29b179349d4f9 @id=1 @mdate=2008-10-28T23:42:14Z @size=186 @type=text/plain @uri=file:///tmp/websearch/doc1 _lfile=doc1 _lpath=file:///tmp/websearch/doc1 _lreal=/tmp/websearch/doc1 One of the nicer features of Hyperestraier is the ability to "dump" an inverted index in a way that lets you see exactly how any one source document contributes to the index as a whole. me% cat doc2.est @digest=aeaeaa3ea042859cfac3279d75d20e7c @id=2 @mdate=2008-10-28T23:42:54Z @size=143 @type=text/plain @uri=file:///tmp/websearch/doc2 _lfile=doc2 _lpath=file:///tmp/websearch/doc2 _lreal=/tmp/websearch/doc2 You can see how words are weighted, and better yet, you can create similar files with additional information and use them to create the index.
You can dump all document drafts from a given index by looking for the string '[UVSET]', which is present in all results:
me% estcmd search -max -1 -dd srch '[UVSET]' --------[02D18ACF20A3A379]-------- VERSION 1.0 NODE local HIT 2 HINT#1 [UVSET] 2 TIME 0.000535 DOCNUM 2 WORDNUM 46 --------[02D18ACF20A3A379]-------- 00000001.est file:///tmp/websearch/doc1 00000002.est file:///tmp/websearch/doc2 --------[02D18ACF20A3A379]--------:END me% ls -lF *.est -rw-r--r-- 1 bin bin 478 Oct 28 19:51 00000001.est -rw-r--r-- 1 bin bin 435 Oct 28 19:51 00000002.est
You can also dump a range of document drafts. If your index contains at least 90 documents, you can extract drafts 20-90 like this:
me% estcmd search -max -1 -dd -attr '@id NUMBT 20 90' srch
By using .est files, you gain complete control over the contents of the searchable index, so you can do things like:
- add soundex/metaphone equivalents for people's names as hidden information to be searched but not displayed
- add metadata (like tags or categories) for documents without having to modify those documents
- add an attribute like the filetype (as returned by file) to your installed programs, so you could do targeted searches specifying scripts vs. compiled binaries vs. static or dynamic libraries
- create your own draft files for "fake" documents, like (say) a table of contents for a tar archive.
Let's add an attribute called "category"; the first document is ok, but the second one is junk. I've modified the draft files to hold only what's needed to create an index by using them as the source:
me% cat doc1.est @title=doc1 @mdate=2008-10-28T23:42:14Z @type=text/plain @uri=file:///tmp/websearch/doc1 category=good One of the nicer features of Hyperestraier is the ability to "dump" an inverted index in a way that lets you see exactly how any one source document contributes to the index as a whole. me% cat doc2.est @title=doc2 @mdate=2008-10-28T23:42:54Z @type=text/plain @uri=file:///tmp/websearch/doc2 category=junk You can see how words are weighted, and better yet, you can create similar files with additional information and use them to create the index.
Now, rebuild the index using just the draft files. We'll create an attribute index for "category", and tell the indexer that "category" is a string:
me% rm -rf srch me% estcmd create -tr -xl -si -attr category str srch estcmd: INFO: status: name=srch dnum=0 wnum=0 fsiz=19924864 ... me% ls *.est | estcmd gather -sd -fe srch - estcmd: INFO: reading list from the standard input ... estcmd: INFO: finished successfully: elapsed time: 0h 0m 0s me% estcmd extkeys srch estcmd: INFO: status: name=srch dnum=2 wnum=46 fsiz=20058247 ... estcmd: INFO: finished successfully: elapsed time: 0h 0m 0s me% estcmd optimize srch estcmd: INFO: status: name=srch dnum=2 wnum=46 fsiz=20059685 ... estcmd: INFO: finished successfully: elapsed time: 0h 0m 0s me% estcmd purge -cl srch estcmd: INFO: status: name=srch dnum=2 wnum=46 fsiz=356996 crnum=0 csiz=0 ... estcmd: INFO: finished successfully: elapsed time: 0h 0m 0s
The word "index" is present in both documents:
me% estcmd search -vu srch index --------[02D18ACF7633EB35]-------- VERSION 1.0 NODE local HIT 2 HINT#1 index 2 TIME 0.000705 DOCNUM 2 WORDNUM 46 VIEW URI --------[02D18ACF7633EB35]-------- 1 file:///tmp/websearch/doc1 2 file:///tmp/websearch/doc2 --------[02D18ACF7633EB35]--------:END
However, if we're only interested in the documents where the category equals "good":
me% estcmd search -vu -attr "category STREQ good" srch index --------[0F3AA0F81FAA276B]-------- VERSION 1.0 NODE local HIT 1 HINT#1 index 2 TIME 0.000938 DOCNUM 2 WORDNUM 46 VIEW URI --------[0F3AA0F81FAA276B]-------- 1 file:///tmp/websearch/doc1 --------[0F3AA0F81FAA276B]--------:END
If all you're interested in is the attribute, you don't need to specify a search string after the index name. Attributes beginning with an @ sign are reserved for use as system attributes; the Hyperestraier documentation covers this in more detail.
Now, let's say you want to improve your search by allowing for misspellings. Metaphone is an algorithm for indexing words by their sound when pronounced in English. For example, the metaphone version of the word "document" is TKMNT.
We'll add some hidden data (the metaphone equivalents for non-trivial words) to each draft file. Hidden data is indented one tab space, and it can be anything that might improve search results:
me% cat doc1.est
@title=doc1
@mdate=2008-10-28T23:42:14Z
@type=text/plain
@uri=file:///tmp/websearch/doc1
category=good
One of the nicer features of Hyperestraier is the ability to "dump"
an inverted index in a way that lets you see exactly how any one source
document contributes to the index as a whole.
ABLT AN AS EKSKTL FTRS HL IN INFRTT INTKS IS KNTRBTS LTS NSR
OF ON PRSTRR SRS TKMNT TMP
me% cat doc2.est
@title=doc2
@mdate=2008-10-28T23:42:54Z
@type=text/plain
@uri=file:///tmp/websearch/doc2
category=junk
You can see how words are weighted, and better yet, you can create
similar files with additional information and use them to create the index.
0M ANT AR ATXNL BTR FLS INFRMXN INTKS KN KRT SMLR US W0 WFTT WRTS YT
The index already exists, so we just need to update it:
me% ls *.est | estcmd gather -cl -sd -fe -cm srch - me% estcmd extkeys srch me% estcmd optimize srch me% estcmd purge -cl srch
The word "information" is in doc2, and the metaphone version is present in the hidden part as INFRMXN. Searching:
me% estcmd search -vu srch INFRMXN --------[064867496E54B5A4]-------- VERSION 1.0 NODE local HIT 1 HINT#1 infrmxn 1 TIME 0.000721 DOCNUM 2 WORDNUM 75 VIEW URI --------[064867496E54B5A4]-------- 4 file:///tmp/websearch/doc2 --------[064867496E54B5A4]--------:END
If your search front-end translates terms into their metaphone equivalents, then you could look for those if the original search came back with nothing. This can be very handy when looking up people's names.
4.5. Fake documents
The best thing about draft files is the ability to use them in place of real documents. When you index things, the process is usually something like this:
- find some real documents
- make the index
- search your documents
Using draft files, you can do this instead:
- rummage around on your system
- create some draft files to store whatever you found
- make the index
- search the draft files instead
Suppose you wanted to index your compiled binaries for some bizarre reason. Among other things, binaries can yield strings (including version information), library dependencies, and functions provided by external libraries:
me% ls -lF /usr/local/sbin/postfix
-rwxr-xr-x 1 root root 262268 Jan 3 2008 /usr/local/sbin/postfix*
me% strings -a /usr/local/sbin/postfix > pf-str.est
[add title, mdate, category lines...]
me% cat pf-str.est
@title=pf-str
@mdate=2008-11-15T01:10:56Z
@type=text/plain
@uri=file:///usr/local/sbin/postfix/strings
category=str
...
sendmail_path
/usr/lib/sendmail
mailq_path
/usr/bin/mailq
newaliases_path
/usr/bin/newaliases
manpage_directory
/usr/local/man
sample_directory
/etc/postfix
readme_directory
html_directory
/dev/null
open /dev/null: %m
-c requires absolute pathname
MAIL_CONFIG
MAIL_DEBUG
MAIL_VERBOSE
PATH
command_directory
daemon_directory
queue_directory
config_directory
mail_owner
setgid_group
bad VERP delimiter character count
...
me% ldd /usr/local/sbin/postfix | awk '{print $1, $3}' | sort > pf-ldd.est
[add title, mdate, category lines...]
me% cat pf-ldd.est
@title=pf-ldd
@mdate=2008-11-15T01:11:06Z
@type=text/plain
@uri=file:///usr/local/sbin/postfix/libs
category=lib
libc.so.1 /lib/libc.so.1
libdb-4.2.so /opt/sfw/lib/libdb-4.2.so
libdoor.so.1 /lib/libdoor.so.1
libgcc_s.so.1 /usr/sfw/lib/libgcc_s.so.1
libgen.so.1 /lib/libgen.so.1
libm.so.2 /lib/libm.so.2
libmd.so.1 /lib/libmd.so.1
libmp.so.2 /lib/libmp.so.2
libnsl.so.1 /lib/libnsl.so.1
libpcre.so.0 /opt/sfw/lib/libpcre.so.0
libresolv.so.2 /lib/libresolv.so.2
libscf.so.1 /lib/libscf.so.1
libsocket.so.1 /lib/libsocket.so.1
libuutil.so.1 /lib/libuutil.so.1
me% nm /usr/local/sbin/postfix | grep 'FUNC.*UNDEF' |
tr "|" " " | awk '{print $8}' | sort > pf-func.est
[add title, mdate, category lines...]
me% cat pf-func.est
@title=pf-func
@mdate=2008-11-15T01:11:28Z
@type=text/plain
@uri=file:///usr/local/sbin/postfix/functions
category=func
abort
atexit
chdir
close
db_create
db_version
execvp
exit
fcntl
free
...
strdup
strerror
strrchr
strspn
syslog
time
tolower
tzset
umask
write
You can change the @uri line to whatever you like; I used the full path to the program plus an indicator showing strings, functions, or libraries. If you created draft files for all your binaries and indexed them, you could (say) find any program that depends on the NSL library:
me% estcmd search -vu -attr "category STREQ lib" srch libnsl --------[02D18ACF794F8BE9]-------- VERSION 1.0 NODE local HIT 1 HINT#1 libnsl 1 TIME 0.001066 DOCNUM 3 WORDNUM 161 VIEW URI --------[02D18ACF794F8BE9]-------- 4 file:///usr/local/sbin/postfix/libs --------[02D18ACF794F8BE9]--------:END
5. Troubleshooting
5.1. Running out of memory?
I've used Hyperestraier to index collections exceeding 1,000,000 documents. The indexer would run without complaint under Solaris, but die periodically on FreeBSD with "out of memory" errors. Since I had around 6 Gb of RAM, I was pretty sure memory wasn't the problem, so I recompiled using a version of Doug Lea's malloc and the problem went away.
The most recent malloc sources are here:
ftp://gee.cs.oswego.edu/pub/misc/malloc-2.8.3.c ftp://gee.cs.oswego.edu/pub/misc/malloc-2.8.3.h
Here's a Makefile suitable for building and installing the library with GCC:
CC = gcc
CPLUS = g++
LIBS = libmalloc.a libcppmalloc.a
DEST = /usr/local/lib
INC = /usr/local/include
all: $(LIBS)
clean:
rm -f $(LIBS) *.o
cppmalloc.o: malloc.c
$(CPLUS) -O -c -I. malloc.c -o cppmalloc.o
install: $(LIBS)
cp $(LIBS) $(DEST)
cp -p malloc.h $(INC)
ranlib $(DEST)/libcppmalloc.a
ranlib $(DEST)/libmalloc.a
libcppmalloc.a: cppmalloc.o
rm -f libcppmalloc.a
ar q libcppmalloc.a cppmalloc.o
libmalloc.a: malloc.o
rm -f libmalloc.a
ar q libmalloc.a malloc.o
malloc.o: malloc.c
$(CC) -O -c -I. malloc.c
To build QDBM and Hyperestraier using this library, change the configure commands to include these environment variables:
LDFLAGS="-L/usr/local/lib -lmalloc" CPPFLAGS="-I/usr/local/include"
5.2. Unwanted documents?
When I searched my home directory for the first time, I got a bunch of unwanted hits from my Mozilla cache. Here's how to get rid of docs without reindexing the entire collection (long lines have been wrapped for readability, and show up as indented).
Move to the directory above the inverted index:
me% cd /search/estraier/home me% ls -l -rwxr-xr-x 1 bin bin 1305 Nov 11 20:53 build* drwxr-xr-x 6 bin bin 512 Nov 14 04:07 srch/
Find the internal Hyperestraier documents representing the cache files:
me% estcmd list srch | grep Cache 15730 file:///home/me/.mozilla/00gh3zwa.default/Cache/259D0872d01 15729 file:///home/me/.mozilla/00gh3zwa.default/Cache/259D586Cd01 15728 file:///home/me/.mozilla/00gh3zwa.default/Cache/259D59F0d01 15727 file:///home/me/.mozilla/00gh3zwa.default/Cache/4CBA5603d01 15742 file:///home/me/.mozilla/00gh3zwa.default/Cache/5B0BAD96d01 15741 file:///home/me/.mozilla/00gh3zwa.default/Cache/E41E6DC7d01
Delete them:
me% estcmd out srch 15730
estcmd: INFO: status: name=srch dnum=15592 wnum=553848 fsiz=111428443
crnum=0 csiz=0 dknum=0
estcmd: INFO: 15730: deleted
estcmd: INFO: closing: name=srch dnum=15591 wnum=553848 fsiz=111428443
crnum=0 csiz=0 dknum=0
6. Feedback
All scripts used in this article are available here.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/vogel.jpg)
Karl Vogel is a Solaris/BSD system administrator at Wright-Patterson Air Force Base, Ohio.
He graduated from Cornell University with a BS in Mechanical and Aerospace Engineering, and joined the Air Force in 1981. After spending a few years on DEC and IBM mainframes, he became a contractor and started using Berkeley Unix on a Pyramid system. He likes FreeBSD, trashy supermarket tabloids, Perl, cats, teen-angst TV shows, and movies.
